
Page 151 - 《软件学报》2020年第11期
P. 151
丁丹 等:场景驱动且自底向上的单体系统微服务拆分方法 3467
(3) 识别共享群组
共享度为单个数据表的特性,不能直接反映在边的权重上.本文首先识别出共享度较高的数据表,再根据这
些表之间的依赖程度进行分类,最终得到若干个共享群组.每一个共享群组包含若干张共享表,且这些表之间存
在较强的依赖关系,倾向于共同提取出来作为一个微服务.
对于第 i 张表 T i ,定义其场景、调用链和 SQL 这 3 个级别的共享度如下.
a) 场景级别的共享度 S Scenario (T i ),等于操作表 T i 的场景数量占总场景数量的比例.
| Scenario ( ) |T
S Scenario () = i (6)
T
i
N Scenario
b) 调用链级别的共享度 S Trace (T i ),等于操作表 T i 的调用链数量占总调用链数量的比例.
|Trace ( ) |T
S () = i (7)
T
Trace i N
Trace
c) SQL 级别的共享度 S SQL (T i ),等于操作表 T i 的 SQL 语句数量占总 SQL 语句数量的比例.
S SQL ()T = | SQL ( ) |T i (8)
i
N SQL
3 个级别的共享度按下式进行加权累加,得到表 T i 的总共享度 S Total (T i ).
S Total (T i )=β 1 ⋅S SQL (T i )+β 2 ⋅S Trace (T i )+β 3 ⋅S Scenario (T i ) (9)
其中,β 1 =0.2,β 2 =0.8,β 3 =1.
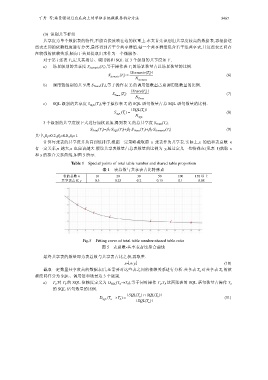
计算每张表的共享度并从高到低排序,根据一定策略截取前 x 张表作为共享表.实际上,x 的值和表总数 n
有一定关系,n 越大,x 也应该越大.假设共享表数量占总表数量的比例为 y,通过定义一些特殊点(见表 1)获取 x
和 y 的拟合关系曲线,如图 5 所示.
Table 1 Special points of total table number and shared table proportion
表 1 表总数与共享表占比特殊点
表的总数 n 10 20 30 50 100 150 以上
共享表占比 y 0.3 0.25 0.2 0.15 0.1 0.08
Fig.5 Fitting curve of total table number-shared table ratio
图 5 表总数-共享表占比拟合曲线
最终共享表的数量即为表总数与共享表占比之积,再取整.
x=⎣n⋅y⎦ (10)
截取一定数量共享度高的数据表后,还需要对这些表之间的依赖关系进行分析.共享表 T a 对共享表 T b 的依
赖度同样分为 SQL、调用链和场景这 3 个级别.
a) T a 对 T b 的 SQL 依赖度定义为 D SQL (T a →T b ),等于同时操作 T a ,T b 这两张表的 SQL 语句数量占操作 T a
的 SQL 语句数量的比例.
| SQL ( )T ∩ SQL ( ) |T
D SQL (T → a T b ) = a b (11)
| SQL ( ) |T a