
Page 148 - 《软件学报》2020年第11期
P. 148
3464 Journal of Software 软件学报 Vol.31, No.11, November 2020
1. 标记权重
5.2. 识别 调整共享群组
共享群组
3. 收集 4. 构建数据 6. 生成数据表
日志 访问轨迹图 共享群组 权重图
测试用例 ⎡ w 11 w 1n ⎤
+ 5.1. 计算数据表 ⎢ ⎥
关联度矩阵 ⎢ ⎥
监控日志 数据访问轨迹图 ⎢ ⎣ 1 n w w ⎥ 数据表权重图
nn⎦
数据表
单体系统 关联度矩阵 7. 数据表图聚类
9. 自底向上搜索,
生成代码拆分方案
2. 配置监控工具 8. 计算拆分开销,
推荐最优方案
最终推荐方案 数据表 多个不同粒度的
手动调整 拆分方案
数据表的归属 数据表拆分方案
调整服务数量或
拆分开销占比
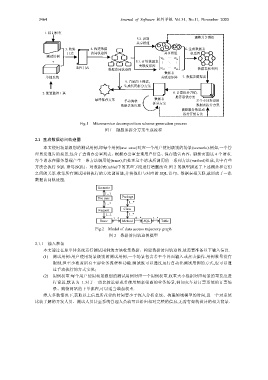
Fig.1 Microservice decomposition scheme generation process
图 1 微服务拆分方案生成流程
2.1 生成数据访问轨迹图
本文使用场景级别的测试用例,即每个用例(use case)对应一个用户使用级别的场景(scenario).例如,一个管
理员发通告的场景,包含了查询办公室列表、根据办公室查询用户信息、保存通告内容、刷新页面这 4 个请求.
每个请求在服务器端产生一条方法调用链(trace),由处理这个请求所调用的一系列方法(method)组成,其中有些
方法会执行 SQL 语句(SQL)、对数据表(table)中的某些字段进行增删改查.图 2 的模型描述了上述概念和它们
之间的关系.收集所有测试用例执行的方法调用链,并将他们与对应的 SQL 语句、数据表相关联,就形成了一张
数据访问轨迹图.
Scenario
1...1
Use case Package
1...* 1...*
Class
Request
1...1 1...*
1...* 0...* 1...*
Trace Method SQL Table
Fig.2 Model of data access trajectory graph
图 2 数据访问轨迹图模型
2.1.1 输入准备
本文通过在原单体系统运行测试用例的方法收集数据、构建数据访问轨迹图,故需要准备以下输入信息.
(1) 测试用例:用户使用场景级别的测试用例,一个场景包含若干个界面输入或点击操作.用例数量没有
限制,但至少覆盖所有主要业务流程和功能.测试既可以通过运行自动化测试用例的方式,也可以通
过手动执行的方式实现;
(2) 用例权重:每个用户使用场景级别的测试用例对应一个用例权重,权重大小根据对应场景的重要度进
行设置,默认为 1.对于一些比较重要或者使用频率很高的业务场景,例如火车站订票系统的订票场
景、购物网站的下单流程,可以适当增加权重.
绝大多数情况下,获取以上信息所花费的时间要少于深入分析系统、构建领域模型的时间,且一个对系统
比较了解的开发人员、测试人员甚至系统管理人员就可以给出相对完整的信息,无需有架构设计的相关背景.