
Page 149 - 《软件学报》2020年第11期
P. 149
丁丹 等:场景驱动且自底向上的单体系统微服务拆分方法 3465
2.1.2 数据访问轨迹图生成
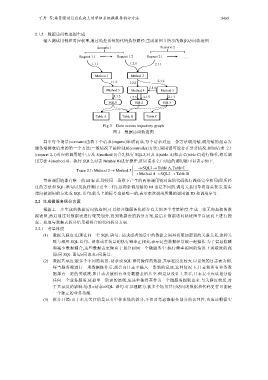
输入测试用例和对应权重,通过监控系统的代码执行路径,生成如图 3 所示的数据访问轨迹图.
Scenario 1 Scenario 2
Request 1.1 Request 1.2 Request 2.1 ...
1.1.1 1.2.1 2.1.1
Method 1 Method 2
1.1.2 1.2.2 2.1.2
2.1.4
Method 3 Method 4 Method 5
1.1.3 1.2.3 2.1.5 2.1.3
SQL1 SQL2 SQL3
Table A Table B Table C
Fig.3 Data access trajectory graph
图 3 数据访问轨迹图
其中每个场景(scenario)由若干个请求(request)串联而成,每个请求对应一条方法调用链,调用链的起点为
服务端接收请求的第一个方法(一般情况下是控制层(controller)方法).调用链可能存在分岔情况,例如请求 2.1
(request 2.1)对应的调用链中,方法 5(method 5)会先执行 SQL3,对表 A(table A)和表 C(table C)进行操作,然后调
用方法 4(method 4)、执行 SQL2,对表 B(table B)进行操作,所以请求 2.1 对应的调用链可以表示如下.
⎧→ SQL3 → Table A,Table C
Trace 2.1: Method 2 → Method 5 ⎨ .
⎩ → Method 4 → SQL2 → Table B
每条调用链都有唯一的 ID 标识,即使同一场景下产生的两条调用链对应的代码执行路径完全相同(即所经
过的方法和 SQL 语句以及执行顺序完全一样),这两条调用链的 ID 也是不同的.调用关系用单向箭头表示,箭头
指向被调用的方法或 SQL 语句,箭头上的标号也是唯一的,表示本次调用所属的调用链 ID 和调用序号.
2.2 生成微服务拆分方案
根据上一步生成的数据访问轨迹图,可以结合微服务化拆分有关的多个考量维度,生成一张无向加权的数
据表图,然后通过对数据表进行聚类划分,得到数据表的拆分方案,最后在数据访问轨迹图中自底向上进行搜
索、获取与数据表拆分结果相符合的代码拆分方案.
2.2.1 考量维度
(1) 数据关联度:出现在同一个 SQL 语句、请求或者场景中的数据之间具有更加密切的关联关系,这种关
联与相应 SQL 语句、请求或者场景的执行频率正相关,表示这些数据经常被一起操作.为了信息隐藏
和减少数据耦合,这些数据表更倾向于划分到同一个微服务中.执行频率相同的情况下关联度的强
弱:同 SQL 语句>同请求>同场景.
(2) 数据共享度:被多个不同的场景、请求或 SQL 语句操作的数据,共享程度比较大.以系统的日志表为例,
每当服务端进行一项数据操作后,都会向日志中插入一条新的记录,这种情况下,日志和所有业务数
据都有一定的关联度,即日志表被所有业务数据表所共享.但是从设计上来看,日志表不应该划分给
任何一个业务服务,依据单一职责的原则,应该单独将其作为一个微服务提取出来.与关联度相反,对
于共享度的影响:场景>请求>SQL 语句.可以理解为,被多个场景共同访问的数据和代码更有可能是
一个独立的业务功能.
(3) 拆分开销:由于本文关注的是已有单体系统的拆分,不仅要考虑微服务划分的合理性,也应该根据实