
Page 238 - 《爆炸与冲击》2026年第5期
P. 238
第 46 卷 王继民,等: 意外爆炸毁伤知识图谱研究 第 5 期
2.3 评价指标
将事件从非结构化的文本中抽取出来,规定只有在触发词和论元都正确抽取的前提下,才能认为当
前的事件抽取结果是正确的。采用事件抽取任务通用的精确率(precision, P)、召回率(recall, R)以及综
合评价指标 F (F1-score) 对知识图谱的构建结果进行评价。
1
T P
P = ×100% (5)
T P + F P
T P
R = ×100% (6)
T P + F N
PR
F 1 = 2 ×100% (7)
R+ P
式中:T 表示真实例,F 表示反实例,F 表示假实例,T 表示真反例。
N
P
N
P
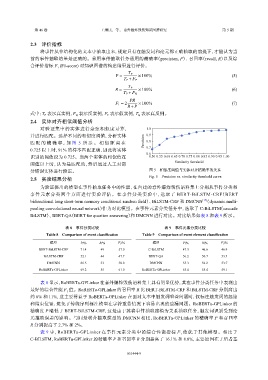
2.4 实体对齐相似阈值分析
对 验 证 集 中 的 实 体 进 行 余 弦 相 似 度 计 算 , 1.0
并进行匹配。选择不同的相似度阈值,分析实体 0.9
匹 配 的 精 确 率 , 如 图 5 所 示 。 相 似 距 离 在 Precision 0.8
0.725 以上时,91% 的样本匹配正确,因此将实体 0.7
0.6
识别的阈值设为 0.725。当两个实体的相似值在 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 1.00
Similarity threshold
阈值以上时,认为是匹配的,然后通过人工对部
分错误实体进行修正。 图 5 相似度阈值与实体对齐精确率的关系
2.5 实验结果分析 Fig. 5 Precision vs. similarity threshold curve
为验证提出的模型在事件抽取任务中的性能,在自建的意外爆炸毁伤语料集上分别从事件分类和
事 件 元 素 分 类 两 个 方 面 进 行 实 验 评 估 。 在 事 件 分 类 实 验 中 , 选 取 了 BERT-BiLSTM-CRF( BERT
bidirectional long short-term memory conditional random field)、BiLSTM-CRF 和 DMCNN [17] (dynamic multi-
pooling convolutional neural network)作为对比模型。在事件元素分类任务中,选取了 C-BiLSTM(cascade
BiLSTM)、BERT-QA(BERT for question answering)和 DMCNN 进行对比。对比结果如表 8 和表 9 所示。
表 8 事件分类比较 表 9 事件元素分类比较
Table 8 Comparison of event classification Table 9 Comparison of event element classification
模型 P/% R/% F 1 /% 模型 P/% R/% F 1 /%
BERT-BiLSTM-CRF 71.4 49 57.0 C-BiLSTM 47.3 46.6 46.9
BiLSTM-CRF 52.1 44 47.7 BERT-QA 56.2 50.7 53.3
DMCNN 66.5 53 58.0 DMCNN 55.3 52.2 53.7
RoBERTa-GPLinker 69.2 55 61.0 RoBERTa-GPLinker 63.4 55.4 59.1
表 8 显示,RoBERTa-GPLinker 在意外爆炸毁伤语料集上具有明显优势,其在事件分类任务中表现出
最好的综合性能 F 值。RoBERTa-GPLinker 的召回率 R 比 BERT-BiLSTM-CRF 和 BiLSTM-CRF 分别高出
1
约 6% 和 11%,这主要得益于 RoBERTa-GPLinker 在面对文本中触发词重叠问题时,仅标注触发词的起始
和结束位置,避免了传统序列标注模型在字符重叠情况下容易出现的遗漏问题。RoBERTa-GPLinker 的
精确度 P 略低于 BERT-BiLSTM-CRF,这是由于其将事件抽取建模为关系抽取任务,触发词识别受到论
元抽取误差的影响。与同是联合抽取模型的 DMCNN 相比,RoBERTa-GPLinker 的精确率 P 和召回率
R 分别提高了 2.7% 和 2%。
表 9 中 , RoBERTa-GPLinker 在 事 件 元 素 分 类 中 的 综 合 性 能 指 标 F 值 优 于 其 他 模 型 。 相 比 于
1
C-BILSTM,RoBERTa-GPLinker 的精确率 P 和召回率 R 分别提高了 16.1% 和 8.8%,主要原因在于后者基
051444-9