
Page 352 - 《软件学报》2020年第9期
P. 352
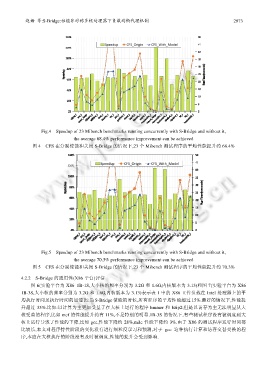
赵姗 等:S-Bridge:性能非对称多核处理器下负载均衡代理机制 2973
Fig.4 Speedup of 23 Mibench benchmarks running concurrently with S-Bridge and without it,
the average 68.4% performance improvement can be achieved
图 4 CFS 在分别使能和关闭 S-Bridge 的情况下,23 个 Mibench 测试程序的平均性能提升约 68.4%
Fig.5 Speedup of 23 Mibench benchmarks running concurrently with S-Bridge and without it,
the average 70.3% performance improvement can be achieved
图 5 CFS 在分别使能和关闭 S-Bridge 的情况下,23 个 Mibench 测试程序的平均性能提升约 70.3%
4.2.2 S-Bridge 的通用性(X86 平台)评估
图 6(实验平台为 X86 1B-1S,大小核的频率分别为 3.2G 和 1.6G,内核版本为 3.13)和图 7(实验平台为 X86
1B-3S,大小核的频率分别为 3.2G 和 1.6G,内核版本为 3.13)表示表 1 中的 X86 工作负载在 Intel 处理器上的平
均执行时间及执行时间的加速比:当 S-Bridge 使能的时候,所有程序的平均性能超过 15%.最好的情况下,性能提
升超过 35%.比如:以计算为主更加受益于在大核上运行的程序 hmmer 和 bzip2;但是以访存为主无法明显从大
核受益的程序,比如 mcf 的性能提升约有 11%,不是特别的明显.1B-3S 的情况下,有些测试程序没有被调度到大
核上运行导致了性能的下降,比如 gcc,性能下降约 28%,milc 性能下降约 3%.由于 X86 的测试程序运行时间都
比较长,本文对程序特性阶段的变化没有进行细粒度学习和预测,对于 gcc 这种执行计算和访存交替变换的程
序,本应在大核执行的阶段没有及时被调度,性能的提升会受到影响.