
Page 349 - 《软件学报》2020年第9期
P. 349
2970 Journal of Software 软件学报 Vol.31, No.9, September 2020
期比例被用来表示程序在大核上运行的受益程度;
(2) 负载模型.此模型基于程序性能模型和 CPU 核之间处理能力差异进行负载扩展因子的评估.
3.2.1 程序性能模型
该性能模型基于 CPI 栈分析程序在大核上运行的受益程度.CPI 栈是经典的被广泛采用的微架构性能评估
模型,CPI 栈主要由基础执行的 CPI 和由各种阻塞事件(比如访存缺失)占用的 CPI 组成,因此,通过基础执行的时
钟周期和由于外部阻塞所占用的时钟周期来计算 CPI 栈.如公式(1)所示:
CPI S =CPI B +CPI S (1)
总的 CPI 由 CPI B 和 CPI S 组成:CPI B 表示真正用来执行指令的周期数,表示用来处理阻塞事件的周期数;
CPI S 是无法有效利用 CPU 的时间.本文通过硬件性能事件程序执行的周期数(cycles)以及指令数(instructions)
比值计算 CPI,CPI S 通过公式(2)计算:
CPI S =M ref ×C miss ×C penalty (2)
其中,M ref 表示每条指令的评价平均访存次数;C miss 表示最后一级缓存(LLC)访问缺失率;C penalty 表示缓存访问缺
失所带来的时间惩罚,C penalty 等于访问内存延时.
根据以上定义,CPI B 通过 1−CPI S 计算.本文定义 CPI_B 表示 CPU 计算资源的需求,由 CPI B 在 CPI 栈所占
的比例计算而来.为了对性能模型的合理性进行评估,本节针对 CPU SPEC2006 的 41 个测试程序进行了实验.
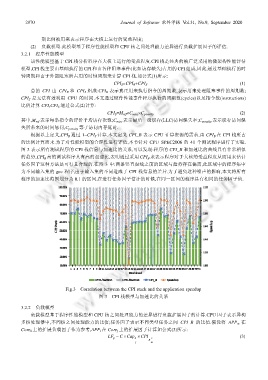
图 3 表示所有测试程序的 CPI 栈信息与加速比的关系,可以发现:程序的 CPI_B 和加速比的曲线具有非常相似
的趋势,CPI B 高的测试程序具有高的加速比,表明通过采用 CPI B 来表示程序对于大核的受益程度从而用来估计
任务因子这种方法是可行且合理的.在图 3 中:两条竖直虚线之前的区域与趋势存在偏离,此区域中的程序集中
为不同输入集的 gcc 程序,由于输入集的不同造成了 CPI 栈信息的差异.为了避免这种噪声的影响,本文将所有
程序的加速比范围划分为 0.1 的区间,在进行任务因子估计的时候,在同一区间的程序具有相同的任务因子值.
Fig.3 Correlation between the CPI stack and the application speedup
图 3 CPI 栈模型与加速比的关系
3.2.2 负载模型
负载模型基于程序性能模型和 CPU 核之间处理能力的差异进行负载扩展因子的计算.CPU 因子表示异构
多核处理器中,不同核之间处理能力的比值;任务因子表示不同类型任务之间 CPI_B 的比值.假设将 APP m 在
Core k 上的扩展负载因子作为参考,APP i 在 Core j 上的扩展因子计算如公式(3)所示:
LF = ij C Cap× k × CPI i (3)
j B m