
Page 216 - 《软件学报》2020年第9期
P. 216
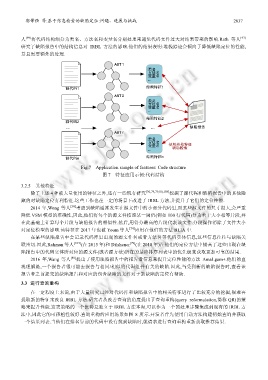
郭肇强 等:基于信息检索的缺陷定位:问题、进展与挑战 2837
人 [99] 将代码结构细分为类名、方法名和变量名分别处理来避免代码文件过大对结果带来的影响.Rath 等人 [97]
研究了缺陷报告中的结构信息对 IRBL 方法的影响.他们的结果表明:堆栈踪迹会倾向于降低缺陷定位的性能,
并且需要额外的处理.
Fig.7 Application sample of features: Code structure
图 7 特征应用示例:代码结构
3.2.5 其他特征
除了上述 4 种被大量使用的特征之外,还有一些现有研究 [30,74,79,80,103] 挖掘了源代码和缺陷报告中的其他隐
藏的对缺陷定位有利特征.这些工作也在一定的场景下改进了 IRBL 方法,并提升了它们的定位性能.
2014 年,Wong 等人 [30] 考虑到缺陷通常发生在源文件中的小部分代码里,而某些源文件的尺寸很大,会严重
降低 VSM 模型的准确性,因此,他们将每个的源文件按照某一阈值(例如 100 行代码)分为若干大小相等片段,并
在此基础上计算每个片段与缺陷报告的相似性.然后,用得分最高的片段代表该文件.分段操作消除了文件大小
对定位模型的影响.该特征在 2017 年也被 Youm 等人 [74] 应用在他们的方法 BLIA 中.
在某些缺陷报告中会记录代码库里出现的源文件名或者方法名等代码实体信息,这些信息往往与缺陷关
联密切.因此,Rahman 等人 [103] (在 2015 年)和 Dilshener [79] (在 2018 年)在他们的定位方法中提高了这些出现在缺
陷报告中的代码实体所对应的源文件(或者源方法)所在的最终排序列表中的优先级来获取更加可靠的结果.
2016 年,Wang 等人 [80] 提出了使用缺陷报告中的报告者信息来提升定位性能的方法 AmaLgam+.他们的直
观理解是,一个报告者很可能去报告与相同/相似的代码组件有关的缺陷.因此,当受到新的缺陷报告时,查看该
报告者之前提交的缺陷报告和对应的包含缺陷的文件对于新缺陷的定位有帮助.
3.3 进行查询重构
在一定程度上来说,由于大量研究已经对代码库和缺陷报告中的相关特征进行了比较充分的挖掘,很难再
提取新的特征来改良 IRBL 方法.研究者从改善查询的角度提出了查询重构(query reformulation,简称 QR)的策
略来提升性能.这类策略的一个优势是独立于 IRBL 方法本身,可以作为一个预处理步骤集成到现有的 IRBL 方
法中,因此它的可移植性较好.查询重构的应用场景如图 8 所示.开发者首先使用自动方法构建初始查询并获取
一个结果列表.当他们在排名靠前的代码中没有找到缺陷时,就请求进行查询重构重新获取推荐结果.