
Page 214 - 《软件学报》2020年第9期
P. 214
郭肇强 等:基于信息检索的缺陷定位:问题、进展与挑战 2835
本历史信息.
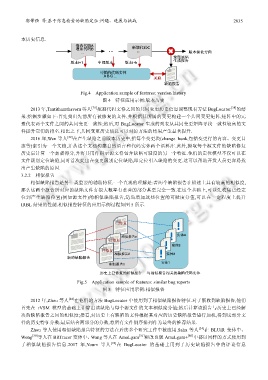
Fig.4 Application sample of features: version history
图 4 特征应用示例:版本历史
2013 年,Tantithamthavorn 等人 [29] 挖掘代码文件之间的共同变更历史信息调整现有方法 BugLocator [28] 的结
果.挖掘步骤如下:首先找出先前所有被修复的文件,并根据其所属的变更构建一个共同变更矩阵,矩阵中的元
素代表两个文件之间的共同变更一致性;然后,对 BugLocator 生成的列表从共同变更矩阵寻找一致性较高的文
件提升它们的排名.相比之下,共同变更历史信息可以对原方法的结果产生显著提升.
2016 年,Wen 等人 [32] 在产生缺陷之前版本历史中,把每个变更块(change hunk,包括变更行的内容、变更日
志等)索引为一个文档,并从这个文档构建自然语言和代码实体两个语料库.此外,提取每个源文件的缺陷修复
历史后计算一个加强得分,并将其用作指示源文件包含缺陷可疑度的另一个特征.他们的定位模型不仅可以在
文件级别定位缺陷,同时首次提出在变更级别定位缺陷,即定位引入缺陷的变更.这可以帮助开发人员更容易找
出产生缺陷的原因.
3.2.2 相似报告
相似缺陷报告是另一类重要的辅助特征.一个直观的理解是:若两个缺陷报告在描述上具有较高的相似度,
那么这两个报告所对应的缺陷文件有很大概率有重叠的部分甚至完全一致.在这个基础上,可以先收集已经定
位到产生缺陷位置(例如源文件)的相似缺陷报告,适当增加这些位置的可疑度分值,可以在一定程度上提升
IRBL 结果的性能.相似报告特征的应用示例过程如图 5 所示.
Fig.5 Application sample of features: similar bug reports
图 5 特征应用示例:相似报告
2012 年,Zhou 等人 [28] 在他们的方法 BugLocator 中使用到了相似缺陷报告特征.对于新收到缺陷报告,他们
首先在 rVSM 模型的基础上计算出该缺陷与每个源文件的文本相似度分值;然后计算该报告与历史上已经解
决的缺陷报告之间的相似度;接着,对历史上有缺陷的文件根据其对应的历史缺陷报告进行加权,得到这部分文
件的历史特征分数;最后结合两部分的分数,将所有文件倒序排列作为最终的推荐结果.
Zhou 等人使用相似缺陷报告特征的方法在后续多个研究工作中被应用.Saha 等人 [24] 在 BLUiR 变体中、
Wong [30] 等人在 BRTracer 变体中、Wang 等人在 AmaLgam [31] 和改良版 AmaLgam+ [80] 中都以同样的方式使用到
了相似缺陷报告信息.2017 年,Youm 等人 [74] 在 BugLocator 的基础上用到了历史缺陷报告中的评论信息