
Page 212 - 《软件学报》2020年第9期
P. 212
郭肇强 等:基于信息检索的缺陷定位:问题、进展与挑战 2833
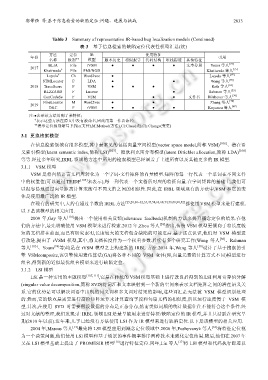
Table 3 Summary of representative IR-based bug localization models (Continued)
表 3 基于信息检索的缺陷定位代表性模型汇总(续)
方法 定位 IR 使用特征
年份 引用
名称 级别 gg 模型 版本历史 相似报告 代码结构 堆栈踪迹 其他特征
BLIA File rVSM ● ● ● ● 文本分段 Youm 等人 [74]
2017 [75]
Khatiwada g File PMI/NGD Khatiwada 等人
Loyola g Ch Word2vec ● Loyola 等人 [95]
STMLocator F LDA ● ● Wang 等人 [98]
2018 TraceScore F VSM ● ● ● Rath 等人 [63]
BLZZARD F Lucene ● Rahman 等人 [35]
ConCodeSe F VSM ● ● 文件名 Dilshener 等人 [79]
FineLocator M Word2vec ● ● Zhang 等人 [78]
2019 [68]
D&C F rVSM ● ● ● ● Koyuncu 等人
注:●表示该方法用到了某特征;
g 表示这些方法在原文中没有被命名,因此用第一作者命名;
gg 表示定位级别缩写 F:File(文件),M:Method(方法),Cl:Class(类),Ch:Change(变更)
3.1 更换检索模型
在信息检索领域有很多模型,其中最常见的包括向量空间模型(vector space model,简称 VSM) [106] 、潜在语
义索引模型(latent semantic index,简称 LSI) [107] 、隐狄利克雷分布模型(latent Dirichlet allocation,简称 LDA) [108]
等等.经过多年研究,IRBL 领域的方法中所用的检索模型已经涵盖了上述所有以及其他更多的 IR 模型.
3.1.1 VSM 模型
VSM 是将自然语言文档库转化为一个字词-文件矩阵的向量模型.矩阵的每一行代表一个单词在不同文件
中的权重值(可以通过 TF.IDF [109] 来表示),每一列代表一个文档所对应的特征向量.在字词矩阵的基础上,我们可
以很容易地通过向量距离计算来衡量不同文档之间的相似性.因此,在 IRBL 领域现有的方法中,VSM 和它的变
体是使用最广泛的 IR 模型.
在现有的研究中,大约有超过半数的 IRBL 方法 [25,28,30−32,35,47,50,63,68,74,79,80,90,92] 都使用 VSM 模型来进行建模.
以下是该模型的相关应用.
2009 年,Gay 等人 [110] 提出一个使用相关反馈(relevance feedback)机制的方法来提升概念定位的结果.在他
们的方法中,最先明确使用 VSM 模型来进行检索.2012 年,Zhou 等人 [28] 指出,传统 VSM 模型更倾向于将长度较
短的文档排在前面,而已有研究表明,长度较大的文档包含缺陷的可能更高.基于这点认识,他们对 VSM 模型进
行改进,提出了 rVSM 模型,其中,将文档长度作为一个权重参数.后续有多个研究工作(Wong 等人 [30] 、Rahman
等人 [103] 、Youm [74] 等)均是在 rVSM 模型之上构建新的 IRBL 方法.2014 年,Wang 等人 [50] 设计了基于搜索的引
擎 VSMcomposite,该引擎使用遗传算法(GA)将各种不同的 VSM 变体(即,向量元素的计算方式不同)模型进行
组合,得到新的近似最优组合模型来进行缺陷定位.
3.1.2 LSI 模型
LSI 是一种实用的主题模型 [107,111] ,它是在传统的 VSM 模型基础上进行改良后得到的.LSI 利用奇异值分解
(singular value decomposition,简称 SVD)将词汇和文本映射到一个新的空间来表示文档矩阵之间的潜在语义关
系.它的优势是可以解决词语中出现的同义词和多义词对结果的影响,这些词汇是无法被 VSM 模型识别处理
的.然而,它的缺点是需要进行高阶矩阵运算来计算查询字段和每篇文档的相似度,所以运行速度慢于 VSM 模
型.其次,在使用 SVD 时需要假设数据的分布是正态分布,然而类似词频的统计数据往往不能符合这个条件.经
过对文献的整理,我们发现:在 IRBL 领域 LSI 是最早被用来进行特征/缺陷定位的 IR 模型,并且只活跃在研究早
期(2010 年以前).近年来,几乎已经没有方法使用 LSI 作为 IR 模型来进行缺陷定位.以下是该模型的相关应用.
2004 年,Marcus 等人 [13] 最先将 LSI 模型应用到概念定位领域中.2006 年,Poshyvanyk 等人 [16] 将特征定位视
为一个决策问题,他们使用 LSI 模型和基于场景的事件概率排序两种技术来强化定位结果.随后,他们在 2007 年
又在 LSI 模型基础上提出了 PROMESIR 模型 [18] 进行特征定位.同年,Liu 等人 [17] 将 LSI 模型和代码执行踪迹以