
Page 151 - 《软件学报》2020年第12期
P. 151
李延超 等:自适应主动半监督学习方法 3817
在增加查询数量时提升性能,但没有提出的方法更加有效.例如:经过 10 轮主动查询后,AdaActive 方法的 NMI
值为 0.862,性能超过所有的对比方法.此外,RAND 方法有时会降低模型的性能,这也可以在之前的分类结果中
发现相似的现象.这进一步说明了选择正确约束对的重要性.值得注意的是:在算法训练的早期阶段,提出方法
的性能接近于其他方法;但随着主动查询数量的增加,性能变得更加强大.这是因为随着训练的加深,样本表示
之间的关联会变得更好.另外,样本代表性的目标函数设计确保无标记数据中的所有样本受到相同概率的选择.
随着主动查询数量的增加,聚类模型越来越鲁棒,从而凸显了提出的方法的优势.在实际中,实验发现算法有时
候会提前收敛.例如,AdaActive 方法在 MNIST 数据集上查询 120 次就已经收敛.实验结果表明,主动学习可以提
高聚类算法的性能.
此外,实验还观察了 RAND,Min-Max,QUIRE,NPU,FASS,URASC,ASCENT 以及 AdaActive 方法在 MNIST
数据集上的 F-measure 表现.对于每次查询,采用粗体突出显示表现最佳的方法.值得注意的是,非随机方法的性
能通常在最初的几次运行中没有显示出统计学上的显着差异.QUIRE 和 Min-Max 方法取得了比随机方法更好
的效果,然而提升的程度没有提出的 AdaActive方法高.与 RAND方法相比,NPU方法的提升是不错的,在 MNIST
数据集上查询 100 次之后的平均性能提升 0.1.URASC 方法的表现更为有效,但提升程度低于 AdaActive 方法.
更重要的是:与使用 NMI 进行评估的结果相似,提出的 AdaActive 方法随着查询数量的增加,算法效果逐渐变好.
因为随着查询的增加,标记和未标记样本之间的关联变得更稳定.就实验效果而言,AdaActive 方法在实验中获
得最优的表现.表 1 列出了 10 次实验中的标准偏差的平均聚类精度.实验总体趋势可以看出:随着查询数量的增
加,聚类算法性能变得越来越好,从而凸显了提出的主动学习方法具有更显着的性能优势.
Table 1 The F-Measure (Mean+_std) of different methods on the MNIST dataset
表 1 各方法在 MNIST 数据集上的 F-Measure (Mean+_std)值
不同数目的主动查询
数据集 方法
30 45 60 75 90 105 120 135 150
RAND 0.76±0.10 0.77±0.15 0.77±0.10 0.76±0.10 0.75±0.10 0.75±0.13 0.75±0.11 0.75±0.10 0.75±0.11
Min-Max 0.81±0.08 0.80±0.10 0.79±0.09 0.79±0.07 0.80±0.09 0.82±0.06 0.84±0.00 0.84±0.00 0.84±0.00
QUIRE 0.77±0.10 0.78±0.08 0.78±0.06 0.80±0.06 0.79±0.01 0.81±0.10 0.82±0.01 0.83±0.11 0.83±0.02
NPU 0.81±0.07 0.82±0.05 0.83±0.06 0.83±0.03 0.84±0.03 0.84±0.01 0.85±0.00 0.85±0.00 0.85±0.00
MNIST
FASS 0.81±0.09 0.83±0.17 0.86±0.01 0.86±0.03 0.87±0.01 0.87±0.02 0.87±0.03 0.89±0.01 0.89±0.02
URASC 0.81±0.08 0.83±0.15 0.85±0.01 0.86±0.05 0.86±0.01 0.87±0.03 0.87±0.02 0.88±0.05 0.88±0.03
ASCENT 0.82±0.10 0.85±0.01 0.87±0.01 0.88±0.03 0.88±0.02 0.89±0.02 0.89±0.01 0.90±0.01 0.91±0.01
AdaActive 0.82±0.10 0.85±0.02 0.87±0.01 0.88±0.02 0.89±0.01 0.89±0.02 0.90±0.01 0.90±0.01 0.92±0.01
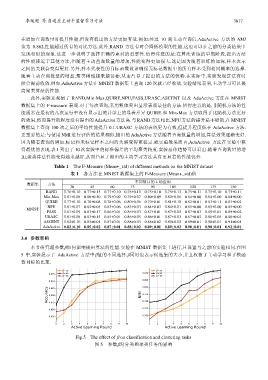
3.4 参数影响
本节研究超参数β如何影响提出算法的性能.实验在 MNIST 数据集上进行,且设置与之前的实验相同.在图
5 中,实验展示了 AdaActive 方法中β值的不同选择.β同时也表示候选集的大小,并且权衡了主动学习和子模函
数目标的比重.
Fig.5 The effect of β on classification and clustering tasks
图 5 参数β对分类和聚类任务的影响