
Page 134 - 《软件学报》2020年第12期
P. 134
3800 Journal of Software 软件学报 Vol.31, No.12, December 2020
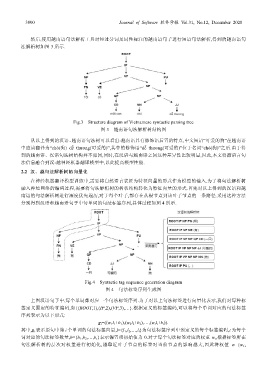
然后,使用越南语句法解析工具对经过分词及词性标注的越南语句子进行短语句法解析,得到的越南语句
法解析树如图 3 所示.
Fig.3 Structure diagram of Vietnamese syntactic parsing tree
图 3 越南语句法解析树结构图
从以上得到的汉语、越南语句法树可以看出:越南语具有修饰语后置的特点,中文短语“可爱的狗”在越南语
中应该翻译为“chó(狗) dễ thương(可爱的)”,其中的修饰语“dễ thương(可爱的)”位于名词“chó(狗)”之后.由于得
到的越南语、汉语句法树结构并不相同,同时,在汉语与越南语之间这种差异性比较明显,因此,本文将源语言句
法信息融合到汉-越神经机器翻译模型中,以此提高模型性能.
2.2 汉、越句法解析树的向量化
在神经机器翻译模型训练中,需要将自然语言表征为特征向量的形式作为模型的输入.为了将句法解析树
融入神经网络的编码过程,需要将句法解析树的树状结构转化为特征向量的形式.首先对以上得到的汉语和越
南语的句法解析树进行深度优先遍历,对于每个叶子,都存在从根节点到该叶子节点的一条路径.采用这种方法
分别得到汉语和越南语句子中每单词的句法标签序列,具体过程如图 4 所示.
Fig.4 Syntactic tag sequence generation diagram
图 4 句法标签序列生成图
上图汉语句子中,每个单词都对应一个句法标签序列.为了对以上句法标签进行向量化表示,我们对每种标
签定义固定的特征编码,如{(ROOT,1),(IP,2),(VP,3),…}.根据定义的标签编码,可以将每个单词对应的句法标签
序列表示为以下形式:
g i =((w 1 l 1 +b 1 ),(w 2 l 2 +b 2 ),…,(w t l t +b t )).
其中,g i 表示原句中第 i 个单词的句法标签向量,l={l 1 ,l 2 ,…,l t }为句法标签序列中预定义的每个标签编码,t 为每个
词对应的句法标签数量,b={b 1 ,b 2 ,…,b t }表示偏置项初始值为 0.对于每个句法标签对应的权重 w t ,根据标签所在
句法解析树的层次对权重进行初始化,越靠近叶子节点的标签对当前节点的影响越大,因此将权值 w={w 1 ,