
Page 116 - 《软件学报》2020年第12期
P. 116
3782 Journal of Software 软件学报 Vol.31, No.12, December 2020
“I-Cent_Modi”的位置-类型复合标签以及 PAD,UNK 和 O 等 3 个单独的位置标签.本任务总共有 17 个标签,可以
在预测类别的同时预测语块边界.
5.1 基于ESIM的蕴含语块-类型识别方法
ESIM 模型也适用于蕴含语块-类型识别任务,在这个任务中,我们的输入与蕴含类型识别任务中 ESIM2 模
型没有差别,如图 4 所示.经过了输入编码层,局部推理层和推理组合层后,我们得到了 C P ,C H .由于语块-类型识别
任务需要得到每个语块的信息,所以我们不做池化操作,如图 4(b)线路所示,直接将 C P ,C H 作为此任务的预测依
据,整合语块的位置信息和蕴含类别,形成 17 个预测标签.
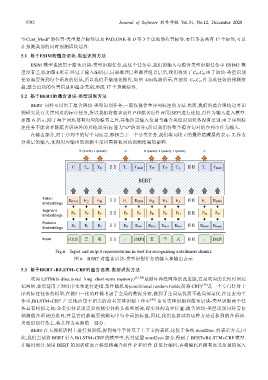
5.2 基于BERT的蕴含语块-类型识别方法
BERT 同样可以用于蕴含语块-类型识别任务,一般仅提供单序列标注的方法.然而,我们的蕴含语块边界识
别研究是有关序列对的标注任务,所以我们将蕴含前件 P 和蕴含后件 H用[SEP]进行连接,再作为输入进入模型.
如图 6 所示,除了每个词块都有对应的标签之外,其他所需输入信息与蕴含类型识别任务没有差别.由于序列标
注任务不能舍弃除蕴含语块外的其他部分(标签为“O”的部分),所以我们将整个蕴含句对的序列串作为输入.
在输出部分,对于序列中的每个词而言,都相当于一个分类任务,我们将词块 i 的最终隐藏层的表示 T i 作为
分类层的输入,使得对应输出的预测不受周围其他词块预测结果的影响.
B-Quantity I-Quantity O B-Quantity I-Quantity I-Quantity O
C T 三 T 名 ⅡⅡ T 。 T [SEP] T 五 T 个 T 人 ⅡⅡ T 。 T [SEP]
BERT
Token
E [CLS] E 三 E 名 ⅡⅡ E 。 E [SEP] E 五 E 个 E 人 ⅡⅡ E 。 E [SEP]
Embeddings
Segment
Embeddings E P E P E P ⅡⅡ E P E P E H E H E H ⅡⅡ E H E H
Position
Embeddings E 0 E 1 E 2 ⅡⅡ E N E N+1 E N+2 E N+3 E N+4 ⅡⅡ E N+M E N+M+1
Input [CLS] 三 名 ⅡⅡ 。 [SEP] 五 个 人 ⅡⅡ 。 [SEP]
Fig.6 Input and output representation in bert for recognizing entailment chunks
图 6 BERT 对蕴含语块-类型识别任务的输入和输出表示
5.3 基于BERT+BiLSTM+CRF的蕴含语块-类型识别方法
双向 LSTM(bi-directional long short-term memory) [37,38] 是循环神经网络的改进版,它是双向的长短时间记
忆网络,非常适用于对时序文本进行建模.条件随机场(conditional random fields,简称 CRF) [39] 是一个专门针对于
序列标注任务的模型,在做归一化的时候考虑了全局的数据分布,做到了全局最优而不是局部最优.在过去的工
作中,BiLSTM+CRF 广泛地应用于相关的命名实体识别工作中 [40] .命名实体识别和蕴含语块-类型识别两个任
务具有相似之处:命名实体识别需要预测实体的头部和尾部,即实体的边界位置;蕴含语块-类型识别同样需要
预测蕴含语块的边界,并且它们都需要预测句中每个词的标签,因此,我们也尝试将这种方法迁移到蕴含语块-
类型识别任务上,将其作为实验的一部分.
BERT 在大规模语料上进行预训练,得到每个字符基于上下文的表征,这优于传统 word2vec 的表示方式,因
此,我们尝试将 BERT 引入 BiLSTM+CRF 的模型中,代替底层 word2vec 部分,得到了 BERT+BiLSTM+CRF 模型.
在编码部分,使用 BERT 的预训练语言模型将蕴含前件 P 和后件 H 进行编码,再将编码后拥有语义信息的嵌入