
Page 257 - 《软件学报》2020年第10期
P. 257
张伟 等:一种时间序列鉴别性特征字典构建算法 3233
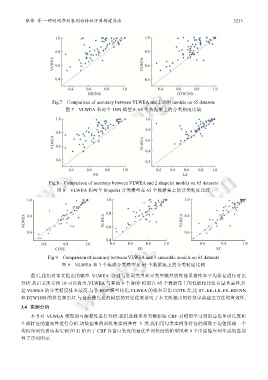
Fig.7 Comparison of accuracy between VLWEA and 2 1NN models on 65 datasets
图 7 VLWEA 和两个 1NN 模型在 65 个数据集上的分类精度比较
Fig.8 Comparison of accuracy between VLWEA and 2 shapelet models on 65 datasets
图 8 VLWEA 和两个 Shapelet 分类模型在 65 个数据集上的分类精度比较
Fig.9 Comparison of accuracy between VLWEA and 3 ensemble models on 65 datasets
图 9 VLWEA 和 3 个集成分类模型在 65 个数据集上的分类精度比较
最后,我们对本文提出的模型 VLWEA 分别与其同类型和异类型模型的性能显著性和平均排名进行对比
分析.从后文所示图 10 可以看出,VLWEA 与其他 6 个 BOP 模型在 65 个数据集上的性能相比没有显著差异,但
是 VLWEA 的分类精度排名最高.与非 BOP 模型相比,VLWEA 的排名只比 COTE 差,比 ST、EE、LS、FS、ED1NN
和 DTW1NN 的排名都更好.与当前最先进的模型的对比结果说明了本文所提出的特征字典建立方法的有效性.
3.4 实例分析
本节对 VLWEA 模型的可解释性进行分析.我们选择多分类数据集 CBF 对模型学习到的最优单词长度和
生成特征的鉴别性进行分析.该数据集的训练集实例共有 3 类.我们用每类实例各特征的频数平均值组成一个
均值序列代表该类实例.图 11 给出了 CBF 各窗口长度的最优单词长度的箱型图和 9 个由原始序列生成的鉴别
性子序列图示.