
Page 108 - 《软件学报》2020年第10期
P. 108
3084 Journal of Software 软件学报 Vol.31, No.10, October 2020
了性能密度(op/multiplier/cycle),即每周期乘法器完成的操作数.以 GPU 的测试数据为基准,RV-CNN 相比于
Cambricon 有 1.16 倍的提升.
(2) 与其他 FPGA 加速器的对比
表 3 列出了本设计与已有的典型 FPGA 加速器的对比结果.由于不同的工作采用了不同的量化策略和不同
的硬件进行部署,因此很难选择出一种有效且精确的比较方法.若以每秒千兆操作数(GOPS)作为性能评估标准,
以前的工作可以实现比我们更好的性能.但是,更高的性能背后是更多的资源消耗,例如 DSP 和 LUT 资源,因而
功耗也会相应增加.若以每瓦特的性能(GOPS/w)作为能效评估标准,与以往的加速器相比,我们的设计在保持灵
活性下仍具有较高的能效.
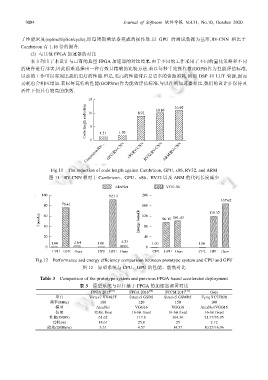
Fig.11 The reduction of code length against Cambricon, GPU, x86, RV32, and ARM
图 11 RV-CNN 相对于 Cambricon、GPU、x86、RV32 以及 ARM 的代码长度减少
Fig.12 Performance and energy efficiency comparison between prototype system and CPU and GPU
图 12 原型系统与 CPU、GPU 的性能、能效对比
Table 3 Comparison of the prototype system and previous FPGA-based accelerator deployment
表 3 原型系统与以往基于 FPGA 的加速器部署对比
FPGA 2015 [23] FPGA 2016 [24] FCCM 2017 [25] Ours
平台 Virtex7 VX485T Stratix5 GSD8 Stratix5 GSMD5 Zynq XC7Z020
频率(MHz) 100 120 150 100
模型 AlexNet VGG16 VGG16 AlexNet/VGG16
位宽 32-bit float 16-bit fixed 16-bit fixed 16-bit fixed
性能(GOPs) 61.62 117.8 364.36 21.77/35.95
功耗(w) 18.61 25.8 25 2.12
能效(GOPs/w) 3.31 4.57 14.57 10.27/16.96