
Page 183 - 《中国电力》2026年第5期
P. 183
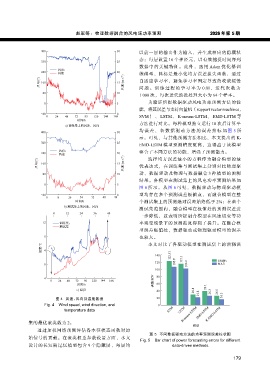
赵军等:物理数据融合的风电场功率预测 2026 年第 5 期
400 30 以前一层的输出作为输入,并生成相应的隐藏状
态;每层设置 16 个神经元,以有效捕捉时间序列
320 25
数据中的关键特征。此外,选用 Adam 优化器训
风向;
240 风速 20 练模型,目标是最小化均方误差损失函数,通过
风向/(°) 160 15 风速/(m·s −1 ) 自适应学习率,避免学习率固定导致的收敛缓慢
问 题 。 训 练 过 程 的 学 习 率 为
0.01, 迭 代 次 数 为
80 10
1 000 次,每次迭代的批处理大小为 64 个样本。
0 5 为验证所提数据驱动风电功率预测方法的性
能,将其误差与支持向量机(support vector machines,
−80 0
0 24 48 72 95 120 144 168 SVM) 、 LSTM、 K-means-LSTM、 EMD-LSTM 等
时间/h
方法进行对比。每种模型独立运行 10 次后计算平
a) 训练集上的风速、风向
400 30 均 误 差 , 各 数 据 驱 动 方 法 的 误 差 指 标 如 图 5 所
示。可见,与其他预测方法相比,本文提出的 K-
320 25
EMD-LSTM 模型预测精度更高,这得益于该模型
风向; 整合了不同方法的功能,增强了预测能力。
240 风速 20
选择均方误差最小的方程作为融合模型的最
风向/(°) 160 15 风速/(m·s −1 ) 优表达式,在训练集与测试集上分别对比物理驱
80 10 动、数据驱动及物理与数据融合 3 种模型的预测
结果。各模型在测试集上的风电功率预测结果如
0 5
图 6 所示。从图 6 可见,数据驱动与物理驱动模
−80 0 型均存在多个预测误差极值点,而融合模型在整
0 8 16 24 32 40 48
时间/h 个测试集上的预测绝对误差始终低于 2%;在整个
b) 测试集上的风速、风向
测试集范围内,融合模型在极值处的预测误差进
0 12 24 36 48
一步降低,这表明所提融合模型在风速切变等功
12 训练集; 率突变场景下的预测精度得到了提升。在融合模
测试集
型误差极值处,数据驱动或物理驱动模型的误差
8 也较大。
温度/℃ 4 本文对比了各驱动模型在测试集上的预测误
140 123.31 115.1
0 120 106.9 102.2 RMSE;
MAE
100
−4 80
0 24 48 72 96 120 144 168 误差/MW
时间/h 60 39.1
c) 温度 40 29.8 21.8 26.3 26.0
图 4 风速、风向及温度数据 20 16.3
Fig. 4 Wind speed, wind direction, and 0
temperature data SVM LSTM K-means-LSTM EMD-LSTM K-EMD-LSTM
集的最优聚类数为 2。
模型
通过加权网络预测评估各本征模态函数对原
图 5 不同数据驱动方法的功率预测误差柱状图
始信号的贡献。在聚类权重参数设置方面,本文
Fig. 5 Bar chart of power forecasting errors for different
设计的长短期记忆模型包含 9 个隐藏层,每层均 data-driven methods
179