
Page 92 - 《中国电力》2026年第4期
P. 92
2026 年 第 59 卷
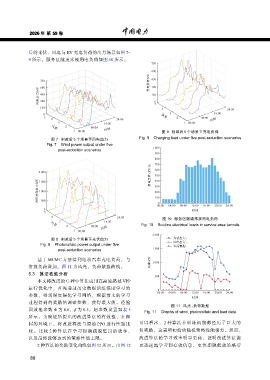
后的光伏、风电与 EV 充电负荷的出力场景如图 7~
9 所示。服务区隧道常规用电负荷如图 10 所示。
750
600
充电负荷/kW 300
750 450
600
风电出力/kW 450 150 0
300
150 5 4 24:00
3 16:00
0 场景
5 2 08:00
4 24:00 时刻
3 16:00 1 00:00
2 08:00
场景
1 00:00 时刻 图 9 削减后 5 个场景下充电负荷
图 7 削减后 5 个场景下风电出力 Fig. 9 Charging load under five post-reduction scenarios
Fig. 7 Wind power output under five
1 000
post-reduction scenarios
900
800
700
用电负荷/(kW·h) 500
2 000 600
光伏发电出力/kW 1 000 300
400
1 500
200
100
500
0
00:00 04:00 08:00 12:00 16:00 20:00 24:00
0 时刻
5
4 24:00 图 10 服务区隧道常规用电负荷
3 16:00
场景
2 08:00 Fig. 10 Routine electrical loads in service area tunnels
时刻
1 00:00
2 000
图 8 削减后 5 个场景下光伏出力 光伏出力;
风电出力;
Fig. 8 Photovoltaic power output under five 负荷数据
post-reduction scenarios 1 500
基于 MCMC 方法得到电动汽车充电负荷,与 功率/kW 1 000
常规负荷叠加。图 11 为风光、负荷数据曲线。
5.3 算法收敛分析
500
本文将改进的 C-PPO 算法应用在高速路域 VPP
运行优化中,首先通过历史数据训练深度学习的
0
00:00 04:00 08:00 12:00 16:00 20:00 24:00
参数,得到深度强化学习网络,根据前文的学习
时刻
过程得到的奖励值调整参数,获得最大值。经验
图 11 风光、负荷数据
回放池参数 Φ 为 0.6,β 为 0.5。超参数设置如表 5
Fig. 11 Graphs of wind, photovoltaic and load data
所示。为验证所提出的改进算法的有效性,在相
同的环境下,将改进算法与原始 PPO 进行性能比 可以看出,2 种算法在训练初期都经历了巨大的
较。比较 2 种算法在学习初期摆脱惩罚的效率, 负奖励,这表明初始的随机策略性能很差。然而,
以及最终能够达到的策略性能上限。 改进算法的学习效率明显更高,证明改进算法能
2 种算法的奖励变化曲线如图 12 所示。由图 12 更迅速地学习到有效信息,更快摆脱低效策略带
88