
Page 141 - 《振动工程学报》2025年第8期
P. 141
第 8 期 刘 杰,等: 不均衡样本下轴承故障的 LSGAN-Swin Transformer 诊断方法 1781
远远大于故障时间,正常类别下采集的数据样本远 正常样本<0.4 时 ,应重点关注样本不均衡对所提
远大于故障类别,当数据比例失衡或故障数据不足 模型产生的影响。
时均会对模型的诊断准确率造成影响,为进一步验 使 用 LSGAN 网 络 生 成 的 数 据 样 本 分 别 均 衡
证 LSGAN 的数据生成能力及 Swin‑T 模型的分类 上述各个不均衡数据集,分别输入 Swin‑T 模型及
能 力 ,以 7∶2∶1 的 比 例 设 置 训 练 集 、验 证 集 、测 试 对比模型中进行训练,其中深度自适应网络(deep
集 ,对 故 障 样 本 与 正 常 样 本 设 置 不 同 比 例 进 行 试 adaptation netowrk,DAN)和 均 衡 分 布 适 应 网 络
验 ,故 障 样 本 与 正 常 样 本 训 练 比 例 及 样 本 数 量 如 (balanced distribution adaptation network,BDA)方
表 3 所示。 法均是常用于故障诊断中的迁移学习方法。将采
集到的各个不均衡比例下的轴承振动信号作为源
表 3 故障样本与正常样本训练比例及样本数量 域 ,与 其 他 对 比 模 型 相 同 的 测 试 集 样 本 作 为 目 标
Tab. 3 Training ratio and sample amount of faulty 域,将源域和目标域数据按 4∶1 的方式划分为训练
samples to normal samples
集和测试集,利用训练集训练 DAN 和 BDA 网络,
故障样本:正常样本
测试集数量 将测试集输入到上述网络中,得到故障诊断结果。
训练比例 样本数量
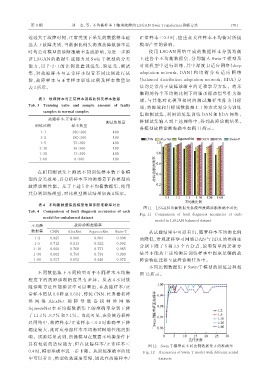
各模型故障诊断准确率如图 11 所示。
1∶1 360∶360 400
1∶2 180∶360 400
1∶5 72∶360 400
1∶10 36∶360 400
1∶30 12∶360 400
1∶60 6∶360 400
在相同测试集上测试不同训练样本数下各模
型的分类效果,以分析样本不均衡场景下各模型的
故障诊断性能。基于上述 5 个不均衡数据集,使用
其分别训练模型,对比模型测试结果如表 4 所示。
表 4 不均衡数据集各模型故障诊断准确率对比
Tab. 4 Comparison of fault diagnosis accuracies of each 图 11 LSGAN 均衡数据集各模型故障诊断准确率对比
Fig. 11 Comparison of fault diagnosis accuracies of each
model for unbalanced dataset
model in LSGAN balanced dataset
不均衡 故障诊断准确率
数据集 CNN AlexNet SqueezeNet Swin-T 从试验结果中可以看出,随着样本不均衡比例
1∶2 0.825 0.900 0.893 0.998 的降低,常规迁移学习网络 DAN 与 BDA 的准确率
1∶5 0.712 0.813 0.822 0.992
分别下降了 5 和 3.9 个百分点,说明简单的迁移方
1∶10 0.660 0.768 0.771 0.985
法并不能从上述均衡后训练样本中提取足够的故
1∶30 0.602 0.750 0.736 0.980
1∶60 0.557 0.652 0.646 0.972 障诊特征迁移至故障诊断任务中。
不同比例数据集下 Swin‑T 模型的训练过程如
不同数据集下不同模型对于不同样本不均衡 图 12 所示。
程度下的故障诊断精度具有差异。从表 4 不同故
障诊断方法性能验证中可以看出,在故障样本/正
常样本值从 0.8 降至 0.6 时,传统 CNN、经典卷积神
经 网 络 AlexNet 和 轻 量 级 卷 积 神 经 网 络
SqueezeNet 在不均衡数据集上的准确率分别下降
了 11.3%、8.7% 和 7.1%。由此可见,在传统卷积神
经网络中,故障样本/正常样本<0.8 时准确率下降
幅度较大,此时应考虑样本不均衡对网络性能的影
响。试验结果表明,所提模型在数据不均衡条件下
具有较强的适应能力,但在故障样本/正常样本< 图 12 Swin-T 模型在不同比例数据集下的准确率
0.4 时,模型准确率进一步下降。从训练准确率曲线 Fig. 12 Accuracies of Swin-T model with different scaled
中可以看出,模型收敛速度变慢,因此在故障样本/ datasets