
Page 140 - 《振动工程学报》2025年第8期
P. 140
1780 振 动 工 程 学 报 第 38 卷
2. 3 LSGAN 模型训练及数据生成 WD) 、最 大 均 值 差 异(maximum mean discrepan‑
[26]
cy,MMD)距离 [27] 衡量分布差异的指标来判定生成
采用表 2 所示的 10 类训练样本,每类样本量为
样本的质量。图 10 展示了所有方法的两种统计指
200,共 2000 个训练样本。采用 4∶1 划分训练集与
标的箱线图结果。箱线图的中位数表示生成样本
测 试 集 的 比 例 ,作 为 LSGAN 训 练 的 输 入 样 本 数
的平均水平 ,箱线图的高度表示轴承 10 种故障类
据 ,训 练 过 程 判 别 器 和 生 成 器 的 损 失 函 数 变 化 如
型生成质量的波动程度,箱线图下方和上方的线表
图 8 所示。
示所有故障类型中统计指标的最小值和最大值。
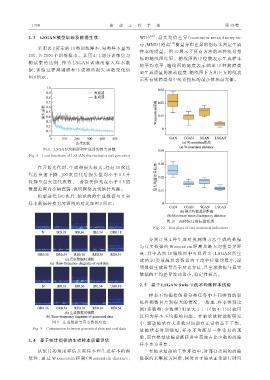
图 8 LSGAN 判别器和生成器的损失函数
Fig. 8 Loss functions of LSGAN discriminator and generator
在开始迭代时,生成器损失较大,经过 50 次迭
代 后 快 速 下 降 ,100 次 迭 代 后 损 失 值 均 小 于 0.5 并
保持至最大迭代次数,二者损失值均在小于 0.5 的
数据范围内小幅震荡,说明网络达到纳什均衡。
模型迭代 500 次后,轴承故障生成数据与真实
样本数据转换为时频图的对比如图 9 所示。
图 10 两种统计指标箱线图
Fig. 10 Box plots of two statistical indicators
分 别 计 算 4 种 生 成 对 抗 网 络 方 法 生 成 的 数 据
与真实数据的 Wasserstein 距离及最大均值差异距
离,其中从图 10 箱线图中可以看出,LSGAN 所生
成的 10 类故障状态数据的平均中位数均最小 ,说
明数据生成质量高于对比方法,且生成数据与真实
数据的平均差异波动最小,稳定性较高。
2. 5 基于 LSGAN-Swin-T 的不均衡样本试验
样本不均衡指的是分类任务中不同类别的训
练样例数目差别很大的情况,一般地,样本类别比
例(多数类∶少数类)明显大于 1∶1(如 4∶1)时就可
以归为样本不均衡的问题。在轴承故障诊断研究
图 9 生成数据与真实数据对比 中,滚动轴承在大多数时间都在正常状态下工作,
Fig. 9 Comparison between generated data and real data
故 障 状 态 时 间 很 短 ,样 本 不 均 衡 是 一 种 常 见 的 现
象,而在模型故障诊断任务中获取占比少数的故障
2. 4 基于统计指标的生成样本质量评估
样本更为重要。
从统计的角度评估真实样本和生成样本的相 在轴承复杂的工作环境中,对部分类别的故障
似 性 ,通 过 Wasserstein 距 离(Wasserstein distance, 数据的采集较为困难,同时由于轴承正常运行时间