
Page 213 - 《软件学报》2025年第12期
P. 213
5594 软件学报 2025 年第 36 卷第 12 期
和百度百科检索模块部署的多线程异步执行功能原理相同, 本节以家谱推理模块为例进行具体实验. 如表 5 所示,
本实验采用的 4 条样例拥有不同的路径排序速度和缺失人物数量, 有下划线和无下划线的“回答情况”分别代表大
模型通过百度百科检索和家谱推理两个模块提供的信息回答对应的样例.
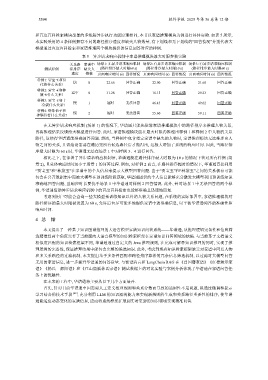
表 5 异步请求响应机制中家谱推理模块最大时限参数实验
关系路 家谱中 场景1: 无异步请求响应机制 场景2: 有异步请求响应机制 场景3: 有异步请求响应机制
测试样例 径排序 缺失人 (路径排序最大时限60 s) (路径排序最大时限10 s) (路径排序最大时限60 s)
速度 物数 页面响应时间 (s) 回答情况 页面响应时间 (s) 回答情况 页面响应时间 (s) 回答情况
样例1: 贾宝玉和贾 快 回答正确 回答正确 回答正确
代善什么关系? 0 22.66 22.90 21.66
样例2: 贾宝玉和林 适中 0 31.28 回答正确 16.15 回答正确 29.23 回答正确
黛玉什么关系?
样例3: 贾宝玉和十
慢 1 超时 无法回答 46.45 回答正确 49.02 回答正确
二金钗什么关系?
样例4: 绛珠仙子和
神瑛侍者什么关系? 慢 2 超时 无法回答 55.60 回答正确 59.11 回答正确
在无异步请求响应机制 (场景 1) 的情况下, 华谱通只能先依靠家谱推理模块中的路径排序来推理人物关系,
再将推理结果反馈给大模型进行问答. 此时, 家谱推理模块能在最大时限内推理出样例 1 和样例 2 中人物的关系
路径, 这使得华谱通能准确回答问题. 然而, 当样例中包含指定家谱中缺失的人物时, 家谱推理模块无法推理出人
物之间的关系, 且该结论需要在遍历完所有候选路径后才能得出, 这极大增加了系统的响应时间. 因此, 当路径排
序最大时限为 60 s 时, 华谱通无法在场景 1 中对样例 3、4 进行回答.
相比之下, 在部署了异步请求响应机制后, 华谱通能在路径排序最大时限为 10 s 的情况下答对所有样例 (场
景 2), 且总体响应时间远小于场景 1 的问答过程. 例如, 对样例 2 而言, 在路径排序超时的情况下, 华谱通直接利用
“贾宝玉”和“林黛玉”在家谱中的个人信息来提示大模型回答问题. 由于“贾宝玉”和“林黛玉”之间的关系极有可能
包含在公开数据集中而被大模型在预训练阶段获取, 华谱通提供的个人信息能够充分激发大模型利用预训练知识
准确地回答问题, 且响应时长要优于场景 1 中华谱通对样例 2 回答情况. 此外, 针对场景 1 中无法回答的两个样
例, 华谱通借助异步请求响应机制中的百度百科检索也能够准确且迅速地回复.
考虑到用户可能会查询一些大模型预训练知识以外的人物关系问题, 在系统的实际部署中, 家谱推理模块对
路径排序的最大时限被设置为 60 s, 允许后台尽可能多地提供家谱中的准确信息, 以平衡华谱通问答的准确性和
响应时间.
4 总 结
本文提出了一种基于知识图谱推理的大语言模型家谱知识问答系统——华谱通, 从推理逻辑完备性和信息筛
选精准性两个角度完善了当前面向大语言模型的知识检索框架在家谱知识问答领域的缺陷. 与当前基于文档语义
相似度匹配的知识检索框架不同, 华谱通通过自定义的 Jena 推理规则, 在完成可解释知识推理的同时, 实现了推
理逻辑的完备性, 保证推理结果中能包含完整的候选知识. 此外, 考虑到现有知识检索框架缺乏对家谱中同名人物
和多关系路径的过滤机制, 本文提出基于多条件匹配和路径排序算法的冗余信息筛选机制, 以过滤对大模型问答
无用的家谱信息, 进一步提升华谱通的问答质量. 与智谱清言和 LangChain RAG 在《曾国藩家谱》《红楼演示家
谱》《杨氏—都阳谱》和《江山鹿溪林氏宗谱》测试数据上的对比实验与案例分析体现了华谱通在家谱问答任
务上的优越性.
在未来的工作中, 华谱通将主要从以下几个方面展开.
首先, 针对目前华谱通中因需要人工定义推理规则和关系分数而导致的适用性不足问题, 拟通过微调和提示
学习结合的技术手段 [42] , 充分利用 LLM 的知识涌现能力来实现新规则的生成和关系路径重要性的排序, 使华谱
通能适应动态变化的家谱信息, 进而将系统框架扩展到实时更新的知识领域实现精准问答.