
Page 462 - 《软件学报》2025年第10期
P. 462
孙锐 等: 隐式多尺度对齐与交互的文本-图像行人重识别方法 4859
们提出的 FED、SCFP 和 MIA 这 3 个模块叠加使用时, 性能分别提高了 5.36%、2.83% 和 2.39%. 综上, 本文所提
出的各个模块都能够有效减少模态间差距, 对文本-图像行人重识别起积极作用.
3.5 超参数影响分析
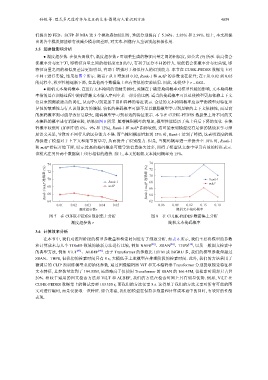
● 温度超参数. 在损失函数中, 温度超参数 τ 可调整生成的特征向量之间的相似度, 如公式 (9) 所示. 较高值会
使概率分布更平坦, 即特征向量之间的相似度更加均匀, 有利于区分不同的行人. 较低值会使概率分布更尖锐, 即
特征向量之间的相似度差异更加明显, 有助于增强对于相似行人的识别能力. 本节在 CUHK-PEDES 数据集上对
不同 τ 进行实验, 结果如图 7 所示. 随着 τ 从 0 增加到 0.02, Rank-1 和 mAP 的参数也在提升; 在 τ 从 0.02 到 0.05
的过程中, 模型性能逐渐下降, 在其他两个数据集上也有类似的实验结果. 因此, 本模型中 τ = 0.02.
● 随机文本掩码概率. 在进行文本掩码的消融实验时, 关键在于确定掩码概率对模型性能的影响. 文本掩码概
率指的是在训练过程中随机屏蔽文本输入序列中某一部分的比例. 适当的掩码概率可以迫使模型更加依赖上下文
信息来预测被遮盖的词汇, 从而学习到更加丰富和鲁棒的特征表示. 合适的文本掩码概率应该平衡模型对特征差
异性的敏感性与行人识别能力的增强. 较低的掩码概率可能不足以激励模型学习到足够的上下文依赖性, 而过高
的掩码概率则可能导致信息缺失, 阻碍模型学习到有效的特征表示. 本节在 CUHK-PEDES 数据集上对不同的文
本掩码的概率进行消融实验, 结果如图 8 所示. 随着掩码概率的增加, 模型性能经历了先上升后下降的变化. 在掩
码概率较低时 (如图中的 6%、9% 和 12%), Rank-1 和 mAP 指标较低, 这可能表明模型没有足够的挑战来学习深
层语义关系, 导致对不同行人的区分能力不强. 而当掩码概率增加到 15% 时, Rank-1 达到了峰值, 这表明适度的挑
战促进了模型对于上下文和细节的学习, 从而提升了识别能力. 但是, 当掩码概率进一步提升至 18% 时, Rank-1
和 mAP 指标开始下降, 暗示过高的掩码概率可能导致信息缺失过多, 阻碍了模型从文本中学习有效的特征表示.
该模式在另外两个数据集上也有相似的趋势. 综上, 本文的随机文本掩码概率为 15%.
74
74 72
Rank-1/mAP 准确率 (%) 70 Rank-1 Rank-1/mAP 准确率 (%) 70 Rank-1
72
68
mAP
mAP
68
66
66
62
64 64
0.01 0.02 0.03 0.04 0.05 0.06 0.09 0.12 0.15 0.18
温度超参数τ 随机文本掩码概率
图 7 在 CUHK-PEDES 数据集上分析 图 8 在 CUHK-PEDES 数据集上分析
温度超参数 τ 随机文本掩码概率
3.6 计算效率分析
在本节中, 我们对推理阶段的模型参数量和检索时间进行了细致分析. 如表 6 所示, 我们主要将模型的参数
和计算成本与几个 TIReID 领域的最新方法进行比较, 例如 NAFS [20] 、SSAN [24] 、TBPS [14] , 以及一般图文检索中
的典型方法, 例如 ViLT [45] 、ALBEF [46] . 由于 Transformer 的参数比 LSTM 或 BiGRU 多, 我们的模型参数量超过
SSAN、TBPS, 但我们的检索时间只有 8 s, 大幅低于上述模型在推理阶段的检索时间. 此外, 我们的方法采用了
微调后的 CLIP 预训练模型来初始化参数, 通过图像编码器 ViT 和文本编码器 Transformer 分别提取视觉特征和
文本特征, 总参数量达到了 194.55M, 虽然略高于仅使用 Transformer 的 SSAN 的 166.45M, 但检索时间却只占其
20%. 相较于通用的图文检索方法如 ViLT 和 ALBEF, 我们的方法在检索时间上具有明显优势. 例如, ViLT 在
CUHK-PEDES 数据集上的测试需要 103 320 s, 而我们的方法仅需 8 s. 这得益于我们的方法无需对所有可能的图
文对进行编码, 而是仅提取一次特征. 综合来看, 我们的模型在保持参数量和计算成本适中的同时, 有较好的性能
表现.