
Page 427 - 《软件学报》2025年第10期
P. 427
4824 软件学报 2025 年第 36 卷第 10 期
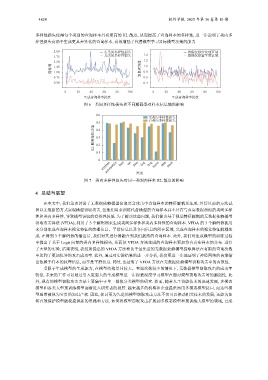
多样性损失使得每个类别的查询样本具有更高的 KL 散度, 从而提高了查询样本的多样性, 进一步说明了类内多
样性损失有助于生成更具差异化的查询样本, 有效增强了代替模型学习目标模型决策的能力.
2.00 有类间多样性损失 图像仅保留纹理区域
无类间多样性损失 1.4 图像仅保留平滑区域
1.75
1.2
1.50
信息熵 1.25 信息熵均值 1.0
0.8
1.00
0.75 0.6
0.50 0.4
0 20 40 60 80 100 0 20 40 60 80 100
生成查询样本批次 生成查询样本批次
图 6 类间多样性损失和不同解码器对样本信息熵的影响
0.6
无类内多样性损失
有类内多样性损失
0.5
KL 散度矩阵均值 0.3
0.4
0.2
0.1
0
airplane bird cat deer dog frog horse ship truck
automobile
类别
图 7 类内多样性损失对同一类别内样本 KL 散度的影响
4 总结与展望
在本文中, 我们重点讨论了无数据依赖模型窃取黑盒攻击中查询样本的特征解耦及生成. 尽管以前的方法试
图以无数据的方式实现模型窃取攻击, 但他们用来训练代替模型的查询样本并不具有与真实数据相似的类间多样
性和类内多样性, 导致模型窃取的有效性较低. 为了解决这些问题, 我们提出基于视觉特征解耦的无数据依赖模型
窃取攻击算法 (VFDA), 利用了 3 个解码器来生成类间多样性和类内多样性的查询样本. VFDA 的 3 个解码器被用
来分别生成查询样本视觉特征的纹理信息、平滑信息以及各自信息的所在区域, 完成查询样本的视觉特征解耦生
成. 在得到 3 个解码器的输出后, 我们对其进行得融合到我们最终的查询样本. 此外, 我们对生成模型的训练过程
中提出了基于 Logit 向量的类内多样性损失, 从而使 VFDA 方法生成的查询样本更加符合真实样本的分布. 进行
了大量的实验, 结果表明, 我们所提出的 VFDA 方法相比于最先进的无数据依赖模型提取算法在有限的查询次数
中达到了更加优异的攻击成功率. 此外, 通过对实验结果的进一步分析, 我们更进一步地证明了神经网络的决策输
出依赖于样本的纹理信息, 而不是平滑信息. 同时, 也证明了 VFDA 方法在无数据依赖模型窃取攻击中的有效性.
受限于生成模型的生成能力, 在模型结构差异较大、查询次数较少的情况下, 无数据模型窃取攻击的成功率
较低. 未来的工作可以通过引入更强大的生成模型进一步探索深度学习模型在面对模型窃取攻击时的脆弱性. 此
外, 现有的模型窃取攻击方法主要集中于单一图像分类模型的研究. 然而, 随着人工智能技术的迅速发展, 多模态
模型和各类大型预训练模型逐渐进入研究者的视野. 越来越多的机构和企业提供商用多模态模型接口, 而这些模
型通常被视为宝贵的知识产权. 因此, 探讨更为先进的模型窃取攻击方法不仅可以推动相关技术的发展, 还能为如
何有效保护模型版权提供新的思路和方法. 如何将模型窃取攻击扩展到多模态模型和预训练大模型的领域, 已成