
Page 425 - 《软件学报》2025年第10期
P. 425
4822 软件学报 2025 年第 36 卷第 10 期
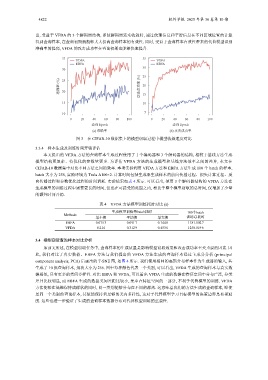
出, 受益于 VFDA 的 3 个解码器结构, 即使解码器还未收敛时, 通过纹理信息和平滑信息在不同区域位置的计算
得到查询样本, 在查询初期就能够大大提高查询样本的有效性. 同时, 受益于查询样本有效性带来的代替模型识别
准确率的提高, VFDA 的攻击成功率在查询初期也能够快速提升.
35 35
VDFA VDFA
EBFA EBFA
30
30 25
准确率 (%) 25 攻击成功率 (%) 20
20
15
15 10
5
10
0 20 40 60 80 100 0 20 40 60 80 100
查询 Epoch 查询 Epoch
(a) 准确率 (b) 攻击成功率
图 3 在 CIFAR-10 数据集上的模型窃取过程中模型收敛速度对比
3.3.4 样本生成及训练时间开销评估
本文提出的 VFDA 方法的查询样本生成过程使用了 1 个编码器和 3 个解码器的结构, 相较于基线方法生成
模型结构更复杂、待优化的参数量更多. 为评估 VFDA 方法的生成模型和基线方法效率之间的差异, 本文在
CIFAR-10 数据集中对比不同方法之间的效率. 本项实验利用 VFDA 方法和 EBFA 方法生成 100 个 batch 的样本,
batch 大小为 256, 实验环境为 Tesla A100×2. 计算时间包括生成器生成样本的前向传播过程、损失计算过程、反
向传播过程和参数优化过程的时间消耗. 实验结果如表 4 所示. 可以看出, 使用 3 个解码器结构的 VFDA 方法在
生成模型的训练过程中需要更长的时间, 但也在可接受的范围之内, 相比于整个模型窃取的总时间, 仅增加了少量
的额外时间开销.
表 4 VFDA 方法模型训练耗时对比 (s)
生成模型训练每batch耗时 100个batch
Methods
最小值 平均值 最大值 训练总耗时
EBFA 0.075 3 0.091 7 0.144 0 1 181.502 7
VFDA 0.214 0.312 9 0.453 6 1 250.019 6
3.4 模型窃取查询样本对比分析
如前文所述, 在模型窃取任务中, 查询样本的生成质量是影响模型窃取效果和攻击成功率至关重要的因素. 因
此, 我们对比了真实数据、EBFA 方法与我们提出的 VFDA 方法生成的查询样本经过主成分分析 (principal
component analysis, PCA) 后画出的 T-SNE 图, 如图 4 所示. 我们使用相同的高斯分布样本作为生成器的输入, 共
生成了 10 批查询样本, 批次大小为 256. 图中每种颜色代表一个类别, 可以看出, VFDA 生成的查询样本与真实数
据相似, 具有更多的类间多样性. 对比 EBFA 和 VFDA, 可以看出 VFDA 生成的数据在特征空间中分布广泛, 分类
差异比较明显, 而 EBFA 生成的数据类间差距比较小, 集中在特征空间的一部分, 不利于代替模型的训练. VFDA
方法能够在低维保持成群状的同时, 同一类别能够分布在不同的群落. 这意味着我们的方法生成的查询样本, 即使
是同一个类别的查询样本, 其依然保持着足够的类内多样性, 这对于代替模型学习目标模型的决策边界是有帮助
的. 这些也进一步验证了生成的查询样本数据分布对代替模型训练的重要性.