
Page 388 - 《软件学报》2025年第10期
P. 388
杨乐 等: BIVM: 类脑计算编译框架及其原型研究 4785
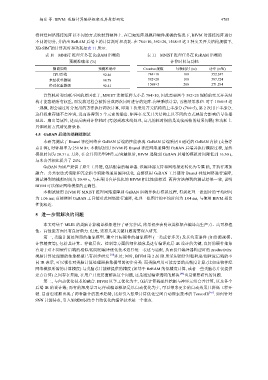
将神经网络连接矩阵以不同的方式映射到硬件上. 在已知矩阵规模和硬件规模的情况下, BIVM 对连接矩阵进行
不同的切分, 并给出 ReRAM 后端上的计算耗时和功耗. 在 784×10, 392×20, 1568×5 这 3 种交叉开关结构规模下,
∗
XB-SIM 的计算耗时和功耗如表 11 所示.
表 10 MNIST 推理任务在 ReRAM 后端的 表 11 MNIST 推理任务在 ReRAM 后端的
预测准确率 (%) 计算时间与功耗
微调策略 预测准确率 Crossbar规模 每帧耗时 (ns) 功率 (mW)
CPU后端 92.46 784×10 100 352.247
未经权重微调 90.78 392×20 100 587.724
经过权重微调 92.41 1 568×5 200 271.294
计算耗时和功耗不同的原因在于, MNIST 连接矩阵大小是 784×10, 因此需要两个 392×20 规模的交叉开关结
构才能容纳所有权重, 而发放过程会被拆分成两次同时进行的矩阵-向量乘法计算, 再将结果求和. 对于 1568×5 这
一规模, 则会通过时分复用的方法执行两次计算, 即第 1 次采用开关结构的上半部分 (784×5), 第 2 次用下半部分,
这样权重存储不会冲突, 进而各得到 5 个元素的输出. 矩阵在交叉开关结构上以不同的方式映射会影响信号传播
延迟、扇出等属性, 进而反映到计算耗时 (考虑到流水线处理, 这儿的耗时指的是连续两帧的结果间隔) 和功耗上.
具体映射方式请见附录 B.
4.5 GaBAN 后端的端到端测试
本研究测试了 Brunel 神经网络在 GaBAN 后端的性能表现. GaBAN 后端采用 8 通道的 GaBAN 内核 (支持浮
点计算), 时钟频率为 250 MHz. 本测试使用 BIVM 将 Brunel 神经网络递降到 GaBAN 后端并执行模拟过程, 最终
模拟时间为 20.31 s. 另外, 在合并同类型神经元/突触组后, BIVM 递降到 GaBAN 后端的模拟时间降低到 16.30 s,
与未合并相比提升了 24%.
GaBAN 为用户提供了原生工具链, 包括配套的编译器. 该编译器支持将网络描述转化为专属 IR, 并执行乘加
融合、公共表达式消除和冗余指令消除等通用编译优化. 直接使用 GaBAN 工具链对 Brunel 神经网络进行递降,
测试得到的模拟时间为 20.49 s, 与未采用合并优化的 BIVM 相比性能相近. 两种方法得到的测试结果一致, 说明
BIVM 可以保证网络模拟的正确性.
本测试使用 BIVM 将 MNIST 推理网络递降到 GaBAN 后端并执行模拟过程, 得到处理一张图片的平均时间
为 1.06 ms; 直接使用 GaBAN 工具链对此网络进行递降, 处理一张图片的平均时间为 1.04 ms, 与使用 BIVM 相比
性能相近.
5 进一步需解决的问题
本文对基于 MLIR 的类脑计算编译框架进行了研究尝试, 结果初步表明该类框架在编译高生产力、高可移植
性、高性能方面具有良好潜力. 但是, 还有几类关键问题需要深入研究.
第一, 类脑计算处理器的抽象模型. 建立目标硬件的抽象模型 (一类或者多类) 及其约束条件 (如资源规模、
计算精度等), 包括其计算、存储层次、控制等方面的细化抽象是进行编译底层 IR 设计的关键, 良好的硬件抽象
有助于对不同硬件后端的相似/相同的编译优化技术进行统一表述与适配, 从而提升编译器构建时的 productivity.
类脑计算处理器的抽象模型已有初步研究 [10] 涉及; 同时, BIVM 第 2 层 IR 所采用的针对粗粒度/细粒度后端的不
同 IR 表示, 可以视作对类脑计算处理器抽象模型的初步分类. 而类脑应用可能需要的高精度计算 (比如生物神经
网络模拟所需的计算精度) 与类脑芯片能够提供的精度 (如基于 ReRAM 的低精度计算, 或者一些类脑芯片仅提供
定点计算) 之间存在差距, 在用户开发层面解决这个问题, 还是通过编译透明的解决 [44] 也是需要研究的问题.
第二, 与自动优化技术的融合. BIVM 以手工优化为主, 包括计算稀疏性挖掘与神经元组合并计算, 以及各个
后端 IR 的设计等; 而有的深度学习运行或编译框架是以自动优化为主, 可以带来更多的自动效果且降低工程开
销. 目前也逐渐出现了两者融合的技术趋势, 比如引入张量计算优化空间自动探索技术的 TensorIR [45] . 如何针对
SNN 计算特点, 引入领域知识结合自动优化的编译技术是一个重点.