
Page 351 - 《软件学报》2025年第10期
P. 351
4748 软件学报 2025 年第 36 卷第 10 期
SFM 和 TSFM 借助支持函数来选择有效的特征表示. 实验结果表明了对图像的深度特征进行集值对象的建模以
及采用两个非平行的超平面分类图像是合理的.
表 5 在医学图像数据集上的实验结果 (%)
数据集 SANP RCRC SOCP SFM SMM UTSVM TSFM
Breast 22.59±5.42 21.76±7.32 21.33±4.09 20.25±6.03 21.2±6.42 21.50±6.49 19.6±5.46
Pneumonia 8.52±3.88 7.32±3.25 7.15±3.02 6.37±2.89 6.65±3.21 7.28±3.02 6.03±2.05
Nodule 25.33±2.67 26.22±3.25 24.22±3.13 24.52±3.26 23.5±4.05 24.62±3.29 22.4±3.12
Synapse 20.45±4.82 19.55±5.02 17.52±4.85 17.26±4.92 16.8±4.92 19.28±4.56 16.1±5.35
3.5 模型超参数的敏感度分析
TSFM 包含多个待确定的超参数. 与 TSVM 的超参数相类似, TSFM 的超参数将影响模型的性能. 当 TSFM 采
用高斯核函数时, 核超参数 σ 会影响原数据的嵌入空间. 本节在 svmguide 数据集上进行了实验, 通过实验研究
TSFM 的超参数对其性能的影响. 该数据集由 3 089 个样本构成, 其中每个样本包含 4 个属性值和 1 个标签. 为了
测试 TSFM 的超参数对其性能的影响, 随机选择一半的样本来训练 TSFM, 其余的样本用作测试集. 与 UCI 实验
部分生成集值数据相类似, 利用均匀分布生成集值数据. 每个集值对象由 10 个事例组成. 为了在三维空间中可视
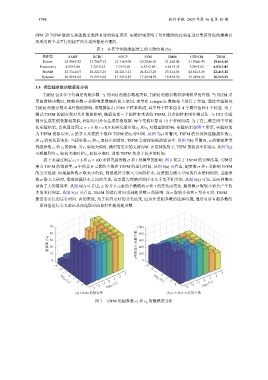
c 2 对模型的影响. 实验结果如图 7 所示, 实验结果
化实验结果, 首先通过固定 σ = 1 和 τ = 0.5 来研究超参数 c 1 和
为 TSFM 的错误率, α 的非 0 元素的个数和 TSFM 的运行时间. 从图 7(a) 可看出, TSFM 的分类性能随超参数 c 1
c 2 取较小的值时, TSFM 会取得较低的错误率. 从图 7(b) 可看出, α 的稀疏性受
和 c 2 的变化而变化. 当超参数 c 1 和
到超参数 c 1 和 c 2 的影响. 当 c 1 取较大值时, 模型有更少的支持向量. 在这种情况下, TSFM 的错误率非常高. 从图 7(c)
可观测到当 c 1 取较大值时和 c 2 取较小值时, 训练 TSFM 花费了较多的时间.
τ 对模型的影响. 图 8 表示了 TSFM 的实验结果, 实验结
接下来通过固定 c 1 = 1 和 c 2 = 100 来研究超参数 σ 和
果为 TSFM 的错误率, α 中的非 0 元素的个数和 TSFM 的运行时间. 从图 8(a) 可看出, 超参数 σ 和 τ 会影响 TSFM
σ 取太小的值, 则很难区分嵌入空间的样本, 这是因为嵌入空间的样本是相似的. 当超参
的分类性能. 如果超参数
数 σ 取太大值时, 很难挖掘样本之间的关系, 这是因为变换后的样本几乎是不相关的. 从图 8(a) 可知, 这两种情况
导致了大的错误率. 从图 8(b) 可看出, α 的非 0 元素的个数随着 σ 和 τ 的变化而变化. 超参数 σ 取较小值会产生较
多的支持向量. 从图 8(c) 可看出, TSFM 的运行时间受到超参数 σ 的影响. 当 σ 取较小值和 τ 为非 0 时, TSFM 一
般需要更长的运行时间. 总的来说, 为了获得更好的分类结果, 应该注意超参数的选择问题, 通常对所有超参数的
一系列值进行交叉验证从而选取对应良好性能的超参数.
50 1 000
40 800
错误率 (%) 30 α中的非 0 元素个数 600
400
20
10 200
0 0
−3 −3
−2 −2
−1 3 −1 3
0 2 0 2
1 1 log 10 (c 2 ) 1 1
2 −1 0 2 −1 0
log 10 (c 2 )
3 −2 log 10 (c 1 ) 3 −3 −2 log 10 (c 1 )
−3
(a) TSFM 的错误率 (b) α 中非 0 元素的个数
图 7 TSFM 的超参数 c 1 和 c 2 的敏感度分析