
Page 348 - 《软件学报》2025年第10期
P. 348
梁志贞 等: 面向集值数据的孪生支持函数机 4745
, , ,
λ 1 λ 2 λ 3 γ 以及核超参数 σ, 超参数设定为 λ 1 = 0.001,λ 2 = 0.001,λ 3 = 2.5/n 1 , 其中 n 1 是一个集值对象包含的数据
点数目. 对于 SMMs, 它包含超参数 C 和核超参数 σ, 超参数 C 取值于集合 {10 ,i = −3,−2,...,2,3}. 对于 UTSVM,
i
i
它包含超参数 c 1 ,c 2 ,c 3 ,c 4 ,ϵ 以及核超参数 σ, 超参数设定为 c 1 = c 3 ,c 2 = c 4 ,ϵ = 0.5, 超参数 c 1 和 c 2 取值于集合 {10 ,i =
i
−3,−2,...,2,3}. 所有方法中使用的核函数是高斯核函数且核超参数 σ 取值于集合 {10 ,i = −3,−2,...,2,3}.
本文使用五折交叉验证来评估各种算法的性能. 为了选择各种模型的适当超参数, 对训练集进行了额外的五
折交叉验证, 以取得各种方法的最优超参数. 表 3 表示了各种方法在数据集上的实验结果, 实验结果为平均错误率
和标准偏差, 最佳结果以黑体显示. 为了评价 TSFM 的稳健性, 把训练集的每一类标签以一定的比例替换成其他类
的标签, 替换的比例为 5%, 这模拟了标签噪声且在标签噪声下产生离群点. 表 4 表示了各种方法在包含标签噪声
的数据集上的实验结果.
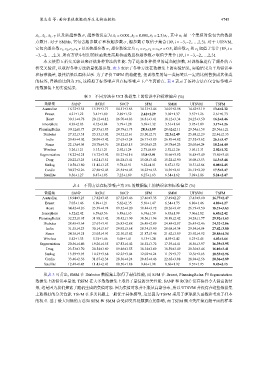
表 3 不同方法在 UCI 数据集上的错误率和标准偏差 (%)
数据集 SANP RCRC SOCP SFM SMM UTSVM TSFM
Australian 16.72±3.55 15.39±3.71 14.51±3.85 14.13±3.46 14.01±2.98 14.62±3.19 13.6±2.32
Breast 4.21±1.22 3.41±1.09 2.89±1.52 2.61±1.29 3.02±1.37 3.57±1.26 2.61±0.73
Heart 30.31±4.78 20.12±4.12 16.70±4.03 16.81±3.41 18.12±3.34 24.25±3.50 16.2±3.46
Ionosphere 4.38±2.03 4.12±3.04 3.79±1.28 3.69±1.32 3.31±1.64 3.95±1.09 3.17±1.26
PlanningRelax 30.12±1.75 29.35±1.85 28.79±1.73 28.3±1.89 28.62±2.11 29.54±1.58 28.56±1.21
Diabetes 27.32±3.51 25.35±3.02 24.32±2.61 23.50±2.71 22.3±2.49 25.68±2.29 22.46±2.35
India 29.45±4.02 28.09±3.42 27.63±3.24 26.71±3.89 26.89±4.02 27.32±3.62 26.1±3.47
Sonar 22.13±4.05 20.78±4.76 20.12±5.15 19.05±5.23 19.78±4.23 20.05±4.24 18.2±4.40
Wireless 3.26±1.21 3.15±1.21 2.92±1.24 2.73±0.89 2.52±2.26 3.03±1.31 2.02±1.32
Segmentation 18.22±4.21 16.72±3.92 15.27±4.16 13.8±3.91 15.66±3.92 16.48±3.49 13.86±3.45
Drug 20.22±3.25 18.21±3.51 16.28±3.41 15.08±3.42 15.22±2.90 18.08±3.53 14.3±3.46
Statlog 10.50±3.80 11.42±3.25 9.78±2.91 9.22±4.01 8.67±3.52 10.51±2.84 8.08±2.45
Cardio 30.27±2.26 27.80±2.45 25.34±4.05 18.23±4.53 18.30±2.81 26.12±2.29 17.5±2.47
Satellite 9.56±1.27 8.47±1.05 7.25±1.89 6.27±1.63 6.34±1.62 7.89±1.86 5.24±2.47
表 4 不同方法在标签噪声为 5% 的数据集上的错误率和标准偏差 (%)
数据集 SANP RCRC SOCP SFM SMM UTSVM TSFM
Australian 18.94±3.23 17.82±3.45 17.32±3.46 17.46±3.35 17.49±2.27 17.45±3.60 16.77±2.47
Breast 7.05±1.46 6.89±1.21 5.62±2.35 5.69±1.47 6.34±1.75 6.80±1.46 4.89±1.27
Heart 34.42±4.26 25.39±4.74 19.52±4.20 18.44±3.72 20.26±3.47 26.73±3.50 18.21±3.63
Ionosphere 6.52±2.42 6.59±3.56 6.89±1.65 6.74±1.59 6.83±1.99 7.06±1.82 6.45±2.42
PlanningRelax 32.25±1.95 31.98±1.42 30.42±1.90 30.56±1.96 30.89±2.42 34.24±1.77 29.92±1.63
Diabetes 28.45±3.64 27.67±3.41 26.83±2.88 26.48±2.89 24.84±2.97 26.45±2.46 24.32±2.86
India 31.55±4.23 30.14±3.67 29.92±3.68 28.34±3.90 28.68±4.34 29.54±4.04 27.42±3.80
Sonar 24.36±4.21 23.05±4.91 22.30±5.62 21.87±5.46 21.62±3.89 23.92±4.92 20.85±4.34
Wireless 5.42±1.33 5.74±1.46 5.08±1.41 5.13±1.24 4.93±2.42 5.23±2.45 4.02±1.64
Segmentation 20.56±4.46 19.26±4.55 17.83±4.42 16.52±3.72 17.39±4.41 18.56±3.97 16.39±3.95
Drug 23.53±3.70 20.54±3.69 19.46±3.55 18.34±3.69 18.59±3.49 20.30±3.46 16.05±3.41
Statlog 13.39±3.93 14.23±3.68 12.25±3.04 12.02±4.24 11.79±3.77 12.56±2.63 10.53±2.96
Cardio 33.46±2.56 31.67±2.34 28.56±4.24 20.45±4.46 22.65±3.08 28.94±2.56 20.36±2.89
Satellite 12.49±1.45 11.43±2.41 10.50±1.88 9.46±1.98 8.60±1.92 9.57±1.95 8.45±2.15
从表 3 可看出, SMM 在 Diabetes 数据集上取得了最佳性能, 而 SFM 在 Breast, PlanningRelax 和 Segmentation
数据集上的错误率最低. TSFM 在大多数数据集上取得了最佳的分类性能. SANP 和 RCRC 没有获得令人满意的结
果, 这是因为我们探索了随机生成的集值对象. 因为集值对象并不服从高斯分布, 所以 UTSVM 并没有在这些数据集
上取得好的分类性能. TSFM 在多类问题上一般优于其他模型, 这是因为 TSFM 采用了弹球损失函数和考虑了样本
的权重. 基于最大间隔的方法如 SFM 和 SMM 会受到交界处数据点的影响, 而 TSFM 侧重关注接近超平面的样本