
Page 320 - 《软件学报》2025年第10期
P. 320
张云婷 等: 中文对抗攻击下的 ChatGPT 鲁棒性评估 4717
和公式 (3), 面向文本分类任务的对抗文本定义的形式化表示如下:
{ ( )
g x i , x ⩽ ε
′
( )
′
f (x i ) , f x , s.t. ( ) i (5)
h x ⩾ φ
i
′
i
当目标模型的输出为包含置信度信息的软标签时, 本节将进一步考虑置信度的约束. 在这种情况下, 结合公
式 (2)–公式 (4), 本节面向文本分类任务的对抗文本定义的形式化表述如下:
( )
g x i , x ⩽ ε
′
i
( ) ( )
′
f (x i ) , f x , s.t. h x ⩾ φ (6)
′
i
i
( )
′
e x ⩾ θ
i
值得注意的是, 尽管本节提供了更为全面的对抗文本形式化定义供读者参考, 但由于后文的工作需观察攻击
有效性随扰动比例的变化情况, 因此后文中的工作在严格意义上来说依旧在广义的对抗文本定义下开展.
2.2 威胁模型
面向文本分类任务的对抗攻击的威胁模型设计通常关注两点, 分别是攻击场景以及模型输出的组成部分.
常见的攻击场景可分为白盒场景以及黑盒场景. 其中, 白盒场景下的攻击表示敌手知道关于目标模型的全部
信息, 包括目标模型的所有训练数据、目标模型的内部结构以及所有参数信息. 而黑盒场景下的攻击则完全相反,
敌手仅允许访问目标模型并得到相应的输出, 对该模型的训练数据、内部结构以及参数等信息一无所知. 相比于
白盒场景, 黑盒场景为物理世界中更为普遍的攻击场景. 因此在本工作中无论是针对中文 BERT 模型还是 ChatGPT
模型的攻击, 均为黑盒场景下的攻击.
目标模型的输出通常有两种, 分别为硬标签和软标签. 其中, 硬标签中仅包含目标模型对输入文本的预测标签;
而软标签中不仅包含预测标签, 还包括该预测标签所对应的分类置信度. 本文将中文 BERT 模型作为中间目标模
型进行攻击, 随后利用对抗样本的可迁移性来攻击最终目标模型 ChatGPT. 在攻击中文 BERT 模型过程中使用的
对抗文本生成方法均为基于词语重要性的攻击方法, 均需要通过目标模型输出的分类置信度来计算词语重要性.
因此对于中文 BERT 这一中间目标模型来说, 本工作选择软标签作为其输出. 而最终目标模型 ChatGPT 作为第三
方提供的生成模型而非专业的分类模型, 其输出只能为硬标签.
3 方法论
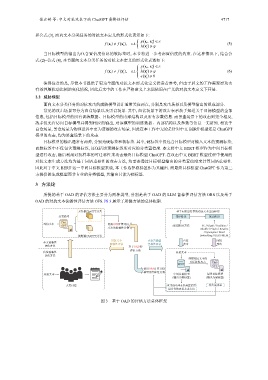
所提的基于 OAD 的评估方法主要分为两种类型, 分别是基于 OAD 的 LLM 鲁棒性评估方法 ORS 以及基于
OAD 的对抗文本流畅性评估方法 OFS. 图 3 展示了所提方法的总体框架.
无法被ChatGPT分类 基于词语重要性的对抗文本生成框架
分类模型 排序阶段 扰动阶段
对抗文本 Chat- 使用OFS计算对抗
GPT 改进的DS方法 SC / Glyph / Tradition /
文本的流畅性分数 Shuffle / Pinyin / Rewrite
/ Synonyms / Word
能够被ChatGPT分类 Embedding / BERT-MLM
对抗文本 大语言模型 直接 间接
本文流畅性 流畅性评估 鲁棒性评估 攻击 攻击
评估方法 基于OAD的
评估方法
传统流畅性 对抗文本
评估方法
利用对抗文本的
可迁移性攻击 Chat-
BERT
GPT
使用ORS计算目标
模型的鲁棒性分数
对抗文本 中间目标模型 最终目标模型
(输出为软标签) (输出为硬标签)
人类评估 攻击成功率&以高置信度 攻击成功率
误分类的对抗文本占比
图 3 基于 OAD 的评估方法总体框架