
Page 290 - 《软件学报》2025年第10期
P. 290
李靓果 等: 结合大语言模型和领域知识库的证券规则规约方法 4687
习示例为 1 篇文档时, 模型的上下文长度达到上限. 在需求信息抽取任务中, 我们使用同样的策略对模型进行微调
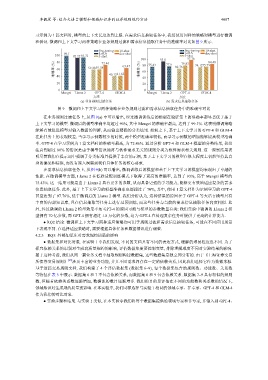
和验证. 微调和上下文学习两种策略在业务规则过滤和需求信息抽取任务中的准确率对比如图 9 所示.
fine-tuning 10-shot fine-tuning 10-shot
99.1 LoRA doc-shot LoRA doc-shot
100 92.22 93.71 5-shot 5-shot
100 93.0 79.83 97.76 84.48
80
准确率 (%) 60 59.2859.58 63.47 准确率 (%) 80 75.43 77.6 69.76 74.1275.79
72.46
60
40.12 41.62
40
40
20 20
0 0
Mengzi Llama 2 GPT-4 GLM-4 Mengzi Llama 2 GPT-4 GLM-4
方法 方法
(a) 业务规则过滤任务 (b) 需求信息抽取任务
图 9 微调和上下文学习两种策略在业务规则过滤和需求信息抽取任务中的准确率对比
在业务规则过滤任务上, 从图 9(a) 中可以看出, 经过微调训练后的模型在验证集上的准确率都显著优于基于
上下文学习的模型. 微调后的模型准确率均超过 90%, 其中 Mengzi 的准确率最高, 达到了 99.1%. 这表明微调策略
能够有效促进模型对输入数据的理解, 从而输出精确的分类结果. 相较之下, 基于上下文学习的 GPT-4 和 GLM-4
在此任务上的表现较差. 当学习示例数较少的时候, 两个模型准确率较低, 而学习示例数的增加能够提高模型准确
率. GPT-4 在学习示例为 1 篇文档时的准确率最高, 为 72.46%. 通过分析 GPT-4 和 GLM-4 模型的分类结果, 我们
注意到超过 80% 的错误是由于模型错误地将与软件需求无关的规则分类为软件需求相关规则. 这一观察结果表
明尽管我们在提示词中强调了分类标准并提供了丰富的示例, 基于上下文学习的模型在很大程度上仍然坚持其自
身的偏见和标准, 而没有深入洞察到我们具体任务的核心要求.
在需求信息抽取任务上, 从图 9(b) 可以看出, 微调训练后的模型和基于上下文学习的模型均表现出了卓越的
性能. 在微调模型方面, Llama 2 在低秩适配训练模式下取得了更高的准确率, 达到了 93%, 高于 Mengzi 模型的
75.43%. 这一结果可能是由于 Llama 2 具有更多的参数, 从而具备更强的学习能力, 能够更有效地适应复杂的需求
信息抽取任务. 此外, 基于上下文学习的模型准确率也都超过了 70%, 其中, 使用 1 篇文档作为示例学习的 GPT-4
甚至达到了 97.76%, 优于微调后的 Llama 2 模型. 我们分析认为, 这种结果的原因在于 GPT-4 等大语言模型具有
丰富的内部知识库, 且在信息抽取等任务上进行过预训练, 而这些任务与当前的需求信息抽取任务高度相似. 此
外, 经过微调的 Llama 2 模型效果不如 GPT-4 的原因可能与模型的参数数量有关: 我们实验中微调的 Llama 2 模
型拥有 70 亿参数, 而 GPT-4 拥有超过 1.8 万亿的参数, 这为 GPT-4 在处理复杂任务时提供了更高的计算能力.
● RQ2 结论: 微调和上下文学习两种适应策略均可用于规则过滤和需求信息抽取任务, 可能在不同应用场景
下表现不同. 在选择适应策略时, 需要根据具体任务和数据情况进行调整.
4.2.3 RQ3: 外部知识库对需求规约质量的影响
● 数据集和对比对象. 在实验 1 中我们发现, 不同的文档具有不同的表达方式, 理解的难易程度也不同. 为了
探究依赖关系的识别对生成高质量规约的影响, 评估数据集需要控制变量, 排除理解难度不同对实验结果的影响.
基于这种考虑, 我们从同一篇业务文档中抽取规则构建数据集, 这些数据集是独立同分布的. 由于《上海证券交易
所债券交易规则》 [25] 涉及丰富的业务功能, 并且不同需求间存在一定的依赖关系, 因此我们选择它作为数据来源.
基于这篇交易规则文档, 我们构建了 4 个评估数据集 (数据集 6–9), 每个数据集包含的规则数、功能数、关系数
等特征在表 5 中展示. 数据集 6 和 7 不包含依赖关系, 而数据集 8 和 9 包含依赖关系. 数据集 7–9 具有相似的规则
数, 但随着依赖关系数逐渐增加, 数据流的数目逐渐增多. 我们的目的是评估在不同的功能数和关系数的情况下,
领域知识对生成规约质量的影响. 在本实验中, 我们同样选择与实验 1 相同的领域专家、非专家、GPT-4 和 GLM-4
作为我们的对比对象.
● 实验步骤和结果. 与实验 1 类似, 在本实验中我们将每个数据集提供给领域专家和非专家, 并输入到 GPT-4、