
Page 258 - 《软件学报》2025年第10期
P. 258
吴泊逾 等: 干扰惰性序列的连续决策模型模糊测试 4655
100% 的非惰性召回率. 这意味着强化学习得到的策略可以让测试序列的密度分布更加明显, 应用本方法的效果更
好. 此外, 我们也可以观察到, 在 MARL+CoopNavi, 惰性序列的召回率也到达 42.5%, 这也进一步解释了为什么在
RQ1 中该测试配置的测试性能提升的最多.
表 3 惰性序列预测模型的性能 (%)
测试配置 P is R is P nis R nis
RL+CARLA 100.0 13.1 4.3 100.0
IL+CARLA 97.6 25.5 4.7 85.7
RL+BipedalWalker 100.0 2.8 1.3 100.0
MARL+CoopNavi 99.8 42.5 0.1 66.7
注: P表示准确率, R表示召回率, 下标is, nis分别表示惰性和非惰性序列
问题 2 评价结论: IIFuzzing 的惰性序列预测模型 InertS-Pred 可以到达很好的惰性序列预测准确率, 同时非惰
性序列的预测召回率在 66.7%–100%, 平均可达 88%. 这意味着 IIFuzzing 放行非惰性序列的风险较小, 可以准确跳
过不太可能触发失效事故的测试序列, 从而在同一测试周期中留下更多的测试资源来探索更大的测试用例空间.
4.5.3 IIFuzzing 探测到的失效事故的多样性 (RQ3)
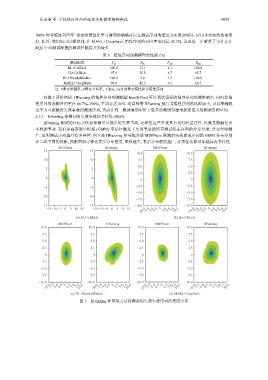
IIFuzzing 测试的目标不仅要探测尽可能多的失效事故, 还希望这些事故具有更好的差异性, 也就是能触发更
多样的事故. 我们用高斯混合模型 (GMM) 来估计触发了失效事故的所有测试状态序列的分布密度. 分布密度越
广, 说明测试序列越具有多样性. 图 5 是 IIFuzzing 和基线方法 MDPFuzz 探测的失效事故序列的 GMM 分布分别
在二维平面的投影, 投影面积可视化表示分布密度, 面积越大, 表示分布密度越广, 亦表征估算对象越具有多样性.
MDPFuzz IIFuzzing MDPFuzz IIFuzzing
15 15
10.0 10.0
10 10 7.5 7.5
5.0 5.0
5 5
2.5 2.5
0 0
0 0
−5 −5 −2.5 −2.5
−5.0 −5.0
−10 −10
−7.5 −7.5
−15 −15 −10.0 −10.0
−15 −10 −5 0 5 10 15 −15 −10 −5 0 5 10 15 0 0
−10.0 −7.5 −5.0 −2.5 2.5 5.0 7.5 10.0 −10.0 −7.5 −5.0 −2.5 2.5 5.0 7.5 10.0
(a) RL+CARLA (b) IL+CARLA
MDPFuzz IIFuzzing MDPFuzz IIFuzzing
10.0 10.0 10.0 10.0
7.5 7.5 7.5 7.5
5.0 5.0 5.0 5.0
2.5 2.5 2.5 2.5
0 0 0 0
−2.5 −2.5 −2.5 −2.5
−5.0 −5.0 −5.0 −5.0
−7.5 −7.5 −7.5 −7.5
−10.0 −10.0 −10.0 −10.0
−10.0 −7.5 −5.0 −2.5 0 2.5 5.0 7.5 10.0 −10.0 −7.5 −5.0 −2.5 0 2.5 5.0 7.5 10.0 −10.0 −7.5 −5.0 −2.5 0 2.5 5.0 7.5 10.0 −10.0 −7.5 −5.0 −2.5 0 2.5 5.0 7.5 10.0
(c) RL+BipedalWalker (d) MARL+CoopNavi
图 5 IIFuzzing 和基线方法探测到的失效事故序列的密度分布