
Page 88 - 《软件学报》2025年第9期
P. 88
韩柳彤 等: 面向 RISC-V 向量扩展的高性能算法库优化方法 3999
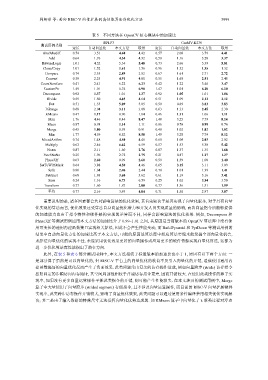
表 5 不同方法在 OpenCV 核心模块中的加速比
BPI-F3 CanMV-K230
测试用例类别
定长 自动向量化 本文方法 联用 定长 自动向量化 本文方法 联用
Abs/Absdiff 0.74 3.51 4.60 4.42 0.57 2.06 3.79 4.41
Add 0.64 1.76 4.34 4.32 0.58 1.16 3.20 3.37
BitwiseLogic 1.01 4.52 5.34 5.48 0.73 2.66 5.39 5.81
Clone/Copy 1.01 1.52 1.61 1.56 0.96 1.32 1.35 1.32
Compare 0.74 2.55 2.89 2.82 0.67 1.61 2.71 2.72
Convert 0.59 2.25 4.91 4.88 0.55 1.68 2.51 2.48
CountNonZero 0.41 2.41 6.22 6.23 0.42 1.22 3.46 3.47
CustomPtr 1.49 1.01 6.74 6.90 1.47 1.01 6.10 6.10
Decompose 0.92 1.37 1.01 1.37 0.92 1.05 1.01 1.06
Divide 0.59 1.50 4.65 4.64 0.51 1.09 2.12 2.12
Dot 0.51 1.55 5.09 5.05 0.50 0.89 3.83 3.83
InRange 0.68 2.04 3.11 3.08 0.63 1.33 2.45 2.30
KMeans 0.47 1.17 0.90 1.04 0.46 1.11 1.06 1.11
Max 1.76 4.46 8.44 8.47 1.48 3.25 7.79 8.14
Mean 0.87 0.98 1.14 1.11 0.86 0.76 0.99 0.76
Merge 0.45 1.00 0.93 0.91 0.40 1.02 1.02 1.02
Min 1.77 4.59 8.52 8.58 1.49 3.28 7.79 8.12
MixedArithm 0.74 1.48 4.50 4.46 0.60 1.06 2.03 2.02
Multiply 0.62 2.46 6.62 6.59 0.57 1.53 5.38 5.42
Norm 0.87 2.11 1.60 2.76 0.87 1.37 1.35 1.68
PatchNaNs 0.25 1.96 2.72 2.75 0.21 0.87 1.27 1.27
Phase32f 0.63 2.60 0.99 2.60 0.59 1.39 1.00 1.40
SetToWithMask 0.64 3.88 4.58 4.46 0.65 3.15 3.11 3.09
Split 0.80 1.04 2.46 2.44 0.70 1.01 1.39 1.41
Subtract 0.68 1.88 3.68 3.62 0.61 1.19 3.16 3.41
Sum 0.24 1.16 6.73 6.59 0.25 1.02 3.54 3.50
Transform 0.77 1.60 1.87 2.08 0.77 1.36 1.51 1.59
平均 0.77 2.16 3.93 4.04 0.71 1.50 2.97 3.07
需要说明的是, 诸多因素都会共同影响算法的优化效果, 其首先取决于是否实现了向量化版本, 对于具有向量
化实现的算法而言, 优化效果还受算法自身向量优化潜力和开发人员实现质量的影响, 而各向量指令所能够提供
的加速能力也由于指令特性和硬件架构实现的差异而不同, 同样会影响算法的优化效果. 例如, Decompose 和
Phase32f 等测试用例应用本文方法的加速比介于 0.99–1.01 之间, 其原因是当前版本的 OpenCV 算法库中没有使
用可变长的通用内建函数接口实现相关算法, 因此不会产生性能变动; 而 BuildPyramid 和 PyrDown 等测试用例的
结果中自动向量化方法的加速比高于本文方法, 可能的原因是算法库中相应算法实现未能发掘全部向量化机会,
或算法向量优化的实现不佳, 未能采用优化效果更好的向量操作或应用更多的硬件资源实现向量化算法, 这都为
进一步优化算法库性能指出了潜在方向.
此外, 在表 5 和表 6 部分测试用例中, 本文方法相较于标量版本的加速比也小于 1, 原因有以下两个方面: 一
是部分算子虽然是可以向量化的, 但 RISC-V 平台上的向量优化的收益不及引入向量化的开销, 造成使用通用内
建函数编写的向量优化反而产生了负面效果. 此类问题常由复杂的访存操作造成, 例如向量跨步 (stride) 访存指令
按照固定的步幅访问内存地址, 其空间局部性相较于普通访存指令更差, 因而开销较大. 在使用此类操作的算子实
现中, 如果没有更多向量运算操作平摊此类指令的开销, 则可能产生性能损失. 在本文涉及的测试用例中, Merge
算子中大量使用了向量跨步 (strided segment) 存储指令, 且不涉及向量运算操作, 而目前的 RISC-V 向量扩展硬件
实现中, 此类跨步访存操作开销较大, 影响了向量优化效果, 此类问题可以通过使用条件编译禁用相关优化实现解
决; 其二是由于输入数据的特殊尺寸无法发挥向量化优势造成的. 如 KMeans 算子中向量化了 k 聚类过程对浮点