
Page 87 - 《软件学报》2025年第9期
P. 87
3998 软件学报 2025 年第 36 卷第 9 期
512
标量
256
定长
128 自动向量化
可变长
平均执行时间 (ms) 32 8 自动向量化
64
可变长+
16
2 4
1
0
DCT DFT Eye LUT Reduce Rotate Round SorIdx Sort TransposeND Zeros
(a) 不具备向量优化机会的算子
512
标量
256 定长
128 自动向量化
可变长
平均执行时间 (ms) 32 8
64
可变长+自动向量化
16
2 4
1
0
Clone/Copy
Add
SetToWithMask
PatchNaNs
Min
Decompose
CountNonZero
Abs/Absdiff BitwiseLogic Compare Convert CustomPtr Divide Dot InRange KMeans Max Mean Merge MixedArithm Multiply Norm Phase32f Split Subtract Sum Transform
测试用例组
(b) 具备向量优化机会的算子
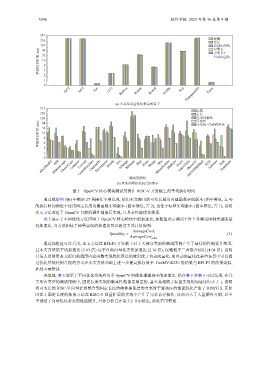
图 5 OpenCV 核心模块测试用例在 RISC-V 开发板上的平均执行时间
通过观察图 5(b) 中剩余 27 类操作不难发现, 使用本文提出的可变长通用内建函数实现版本 (图中黄色, 左 4)
的执行时间都低于使用固定长度内建函数实现版本 (图中绿色, 左 2), 也低于标量实现版本 (图中橙色, 左 1), 说明
本文方法改进了 OpenCV 目前的硬件抽象层实现, 且具有性能优化效果.
表 5 展示了不同优化方法应用于 OpenCV 核心模块中的加速比, 加粗值表示测试平台上各测试用例类型的最
优加速比. 各方法相较于标量实现的加速比可以通过下式计算得到:
AverageCost
SpeedUp = i (1)
i
AverageCost scalar
通过加粗值可以看出, 本文方法在 BPI-F3 开发板上对于大部分类别的测试用例产生了最佳的性能提升效果,
且本文方法的平均加速比 (3.93 倍) 高于自动向量化方法加速比 (2.16 倍), 仅略低于二者联合使用 (4.04 倍). 说明
开发人员使用本文提出的通用内建函数实现优化算法的效果优于自动向量化, 而自动向量化在某些场景中可以通
过优化其他代码片段的方式在本文方法基础上进一步提高执行效率. CanMV-K230 的结果与 BPI-F3 的结果类似,
此处不再赘述.
类似地, 表 6 展示了不同优化方法应用于 OpenCV 图像处理模块中的加速比. 结合表 5 和表 6 可以发现, 在几
乎所有类型的测试用例中, 固定长度实现的版本性能都是最差的, 甚至其相较于标量实现的加速比也小于 1, 说明
将可变长的 RISC-V 向量扩展整合到固定长度的硬件抽象层的方案对于算法库的性能优化产生了负面作用, 其原
因在于固定长度的抽象方法在 RISC-V 向量扩展的实现中产生了冗余访存操作, 从而引入了大量额外开销, 以至
于抵消了向量优化带来的性能提升, 具体分析已在第 3.2 节中给出, 此处不再赘述.