
Page 486 - 《软件学报》2025年第9期
P. 486
朱建秋 等: 视觉注意力和域特征融合的人脸活体检测方法 4397
充分地利用了人脸图像的内容和风格特征, 并且通过合理的监督策略缩小了源域和目标域的分布差异, 从而显著
提升了模型在目标域上的检测能力.
3.5 3.0
O&C&I to M O&C&I to M
3.0 O&M&I to C O&M&I to C
2.5
O&C&M to I O&C&M to I
2.5
I&C&M to O 2.0 I&C&M to O
2.0
Loss 1.5 Loss 1.5
1.0
1.0
0.5 0.5
0 0
0 20 40 60 80 100 120 140 0 20 40 60 80 100 120 140
Epoch Epoch
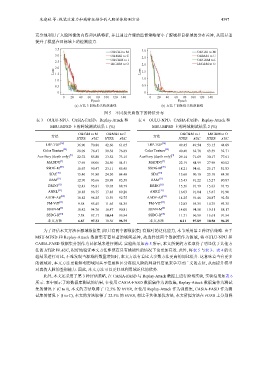
(a) 方法 3 训练损失收敛曲线 (b) 方法 7 训练损失收敛曲线
图 5 不同损失函数下的特征分布
表 3 OULU-NPU、CASIA-FASD、Replay-Attack 和 表 4 OULU-NPU、CASIA-FASD、Replay-Attack 和
MSU-MFSD 上的跨域测试结果 1 (%) MSU-MFSD 上的跨域测试结果 2 (%)
O&C&I to M O&M&I to C O&C&M to I I&C&M to O
方法 方法
HTER AUC HTER AUC HTER AUC HTER AUC
[28] [28]
LBP-TOP 36.90 70.80 42.60 61.05 LBP-TOP 49.45 49.54 53.15 44.09
Color Texture [29] 28.09 78.47 30.58 76.89 Color Texture [29] 40.40 62.78 63.59 32.71
Auxiliary (depth only) [3] 22.72 85.88 33.52 73.15 Auxiliary (depth only) [3] 29.14 71.69 30.17 77.61
MADDG [7] 17.69 88.06 24.50 84.51 MADDG [7] 22.19 84.99 27.98 80.02
SSDG-M [20] 16.67 90.47 23.11 85.45 SSDG-M [20] 18.21 94.61 25.17 81.83
SDA [30] 15.40 91.80 24.50 84.40 SDA [30] 15.60 90.10 23.10 84.30
DAM [31] 12.70 95.66 20.98 85.58 DAM [31] 15.43 91.22 15.27 90.87
DRDG [32] 12.43 95.81 19.05 88.79 DRDG [32] 15.56 91.79 15.63 91.75
ANRL [33] 10.83 96.75 17.83 89.26 ANRL [33] 16.03 91.04 15.67 91.90
AADF-AS [34] 10.83 96.25 13.59 92.75 AADF-AS [34] 14.25 93.46 20.87 92.58
FM-ViT [35] 9.58 95.45 11.65 94.35 FM-ViT [35] 12.83 95.35 14.75 93.35
SSAN-M [8] 10.42 94.76 16.47 90.81 SSAN-M [8] 14.00 94.58 19.51 88.17
SSDG-R [20] 7.38 97.17 10.44 95.94 SSDG-R [10] 11.71 96.59 15.61 91.54
本文方法 6.67 97.32 10.56 96.75 本文方法 8.21 97.89 10.58 96.25
为了评估本文方法在源域数据集 (即只有两个源数据集) 有限时的泛化能力, 本节采用第 2 种评估策略. 由于
MSU-MFSD 和 Replay-Attack 数据集有着显著的域间差异, 故选择这两个数据集作为源域, 将 OULU-NPU 和
CASIA-FASD 数据集分别作为目标域来进行测试. 实验结果如表 5 所示, 本文所提的方法取得了明显优于其他方
法的 HTER 和 AUC, 很好地验证本文方法即使在具有挑战性的情况下也更加有效. 此外, 将表 5 与表 3、表 4 的实
验结果进行对比, 不难发现当源域的数量增加时, 本文方法有着比大多数方法更高的同比提升. 这意味着当有更多
的源域时, 本文方法更能够利用域间共享信息和区分真假人脸的判别性信息来学习更广义的表征, 从而提升模型
对真伪人脸的鉴别能力. 因此, 本文方法可以更好地利用域泛化的优势.
此外, 本文还采用了第 3 种评估策略, 在 CASIA-FASD 与 Replay-Attack 数据上进行跨域实验, 实验结果如表 6
所示. 表中展示了跨数据库测试的结果, 在使用 CASIA-FASD 数据集作为训练集, Replay-Attack 数据集作为测试
集的情况下 (C to I), 本文的方法取得了 12.3% 的 HTER, 在使用 Replay-Attack 作为训练集, CASIA-FASD 作为测
试集的情况下 (I to C), 本文的方法取得了 22.5% 的 HTER, 相比于其他最优方法, 本文所提方法在 HTER 上分别降