
Page 458 - 《软件学报》2025年第9期
P. 458
苟向阳 等: 高精度滑动窗口模型下的图流三角形近似计数算法 4369
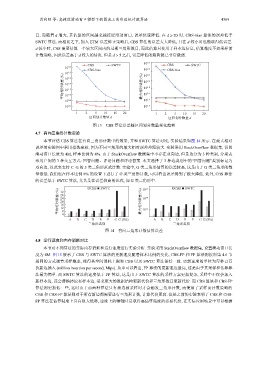
目, 而随着 d 增大, 其估算的区间越来越接近滑动窗口, 误差快速降低. 在 d ⩾ 20 时, CBS-bias 算法的误差低于
SWTC 算法. 而相比之下, 加入 ETM 误差修正策略后, CBS 算法的误差大大降低, 且在 d 较小时也能取得低误差.
d 较小时, CBS 需要估算一个较大区间内的过期三角形数目, 而此估算只使用了样本边信息, 估算精度不如采样前
计数策略, 因此误差高于 d 较大的情况. 但是 d > 5 之后, 误差降低的趋势就已非常微弱.
10 2.6
CBS SWTC CBS SWTC
10 2.0
CBS-bias 10 2.4 CBS-bias
10 1.8 10 2.2
平均相对误差 (%) 10 1.4 最大相对误差 (%) 10 2.0
1.6
10
1.8
10
10
1.2
1.6
10
10
0.8
10 1.0 10 1.4
10 0.6 10 1.2
1 2 5 10 15 20 1 2 5 10 15 20
区间划分数量 d 区间划分数量 d
图 13 CBS 算法误差随区间划分数量变化趋势
4.7 有向三角形计数实验
本节评估 CBS 算法在有向三角形计数中的效果, 并和 SWTC 算法对比, 实验结果如图 14 所示. 在最大相对
误差的实验图中采用指数坐标, 因为不同三角形的最大相对误差差距较大. 实验采用 StackOverflow 数据集, 设置
滑动窗口长度为 4M, 样本比例为 4%. 由于 StackOverflow 数据集中不存在双向边, 但是边分为 3 种类别, 分别表
示用户间的 3 种交互方式: 回答问题、评论问题和评论答案. 本文选择了 3 种边类别中的“回答问题”类别标记为
双向边, 以此来支持 C–G 的 5 类三角形范式计数. 实验中, G 类三角形估算的误差较高, 这是由于 G 类三角形的数
量很低. 我们也在样本比例 8% 的设置下进行了 G 类三角形计数, 可以看出误差得到了极大降低. 此外, CBS 算法
的误差低于 SWTC 算法, 尤其是在误差较高的范式, 如 G 类三角形中.
32 CBS SWTC 10 2.5 CBS SWTC
平均相对误差 (%) 28 最大相对误差 (%) 10 2.0
24
20
16
12
10
1.5
8
4
A B C D E F G G (8%) A B C D E F G G (8%)
三角形类别 三角形类别
图 14 有向三角形计数估算误差
4.8 运行速度和内存消耗对比
本节对不同算法的实际内存消耗和运行速度进行实验分析. 实验采用 StackOverflow 数据集, 设置滑动窗口长
度为 4M. 图 15 展示了 CBS 与 SWTC 算法的更新速度随着样本比例的变化, CBS-FP 和 FP 算法则按照第 4.6 节
相同的方式调节采样概率, 使得其空间消耗上限和 CBS 以及 SWTC 算法保持一致. 更新速度的单位为每秒百万
次新边插入 (million insertion per second, Mips). 从中可以看出, FP 算法的更新速度最高, 这是由于其采样和估算算
法最为简单. 而 SWTC 算法的速度低于 FP 算法, 这是由于 SWTC 算法的采样方案更加复杂, 采样中不仅会加入
新样本边, 还会替换掉原有样本边, 带来更大的数据结构更新代价和三角形数目更新代价. 而 CBS 算法和 CBS-FP
算法则更加低一些, 这时由于前两种算法只有新边被采样时才会触发三角形计数, 而使用了采样前计数策略的
CBS 和 CBS-FP 算法则对于所有新边都需要进行三角形计数, 计算代价更高. 但是之前的实验表明了 CBS 和 CBS-
FP 算法在估算精度上具有很大优势, 速度上的牺牲时是取得高估算精度的必要代价. 在实际应用场景中可以根据