
Page 456 - 《软件学报》2025年第9期
P. 456
苟向阳 等: 高精度滑动窗口模型下的图流三角形近似计数算法 4367
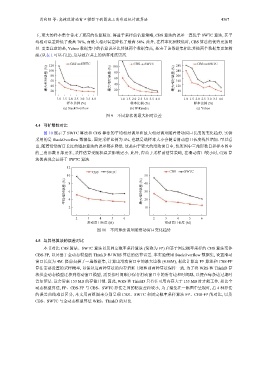
下, 更大的样本集合带来了更高的估算精度. 得益于采样前估算策略, CBS 算法的误差一直优于 SWTC 算法, 其平
均相对误差降低了最高 70%, 而最大相对误差降低了最高 54%. 此外, 在样本比例较低时, CBS 算法的优势更加明
显. 需要注意的是, Yahoo 数据集中的估算误差比其他两个数据集高, 是由于该数据集相比其他两个数据集更加稀
疏 (从表 1 可以看出), 这导致在其上的估算难度更高.
CBS SWTC 100 CBS SWTC 280 CBS SWTC
120
最大相对误差 (%) 80 最大相对误差 (%) 80 最大相对误差 (%) 200
240
100
60
60
160
40
120
40
20
1.0 1.5 2.0 2.5 3.0 3.5 4.0 20 1.0 1.5 2.0 2.5 3.0 3.5 4.0 80 1.0 1.5 2.0 2.5 3.0 3.5 4.0
样本比例 (%) 样本比例 (%) 样本比例 (%)
(a) StackOverflow (b) Wikipedia (c) Yahoo
图 9 不同算法的最大相对误差
4.4 可扩展性对比
图 10 展示了 SWTC 算法和 CBS 算法的平均相对误差和最大相对误差随着滑动窗口长度的变化趋势. 实验
采用的是 StackOverflow 数据集. 固定采样比例为 4%, 也就是说样本大小会随着滑动窗口长度线性增加. 可以看
出, 随着滑动窗口长度的增加算法的误差都在降低. 这是由于更大的滑动窗口中, 快照图中三角形数目和样本图中
的三角形数目都更多, 采样估算受随机误差影响更小. 此外, 得益于采样前估算策略, 在滑动窗口较小时, CBS 算
法的表现会远好于 SWTC 算法.
12
CBS SWTC CBS SWTC
10 50
平均相对误差 (%) 8 6 4 最大相对误差 (%) 40
30
20
2 10
2 3 4 5 6 2 3 4 5 6
滑动窗口长度 (M) 滑动窗口长度 (M)
图 10 不同算法误差随滑动窗口变化趋势
4.5 与其他算法的误差对比
本节对比 CBS 算法、SWTC 算法以及固定概率采样算法 (简称为 FP) 和基于固定概率采样的 CBS 算法变体
CBS-FP, 以及基于全动态模型的 ThinkD 和 WRS 算法的估算误差. 本实验使用 StackOverflow 数据集, 设置滑动
窗口长度为 4M. 提前扫描了一遍数据集, 计算出滑动窗口中的最大边数 (4.88M), 据此计算出 FP 算法和 CBS-FP
算法需要设置的采样概率, 以保证这两种算法的内存消耗上限和前两种算法保持一致. 为了将 WRS 和 ThinkD 算
法从全动态模型迁移到滑动窗口模型, 需要按时间顺序保存滑动窗口中的所有边和时间戳, 以便在每条边过期时
告知算法. 这会带来 153 MB 的存储开销. 因此, WRS 和 ThinkD 只有在可用内存大于 153 MB 时才能工作. 相比全
动态模型算法, FP、CBS-FP 与 CBS、SWTC 算法之间的精度差距较小, 为了避免在一幅图中呈现时, 后 4 种算法
的误差曲线难以区分, 本文用两组图来分别呈现 CBS、SWTC 和固定概率采样算法 FP、CBS-FP 的对比, 以及
CBS、SWTC 与全动态模型算法 WRS、ThinkD 的对比.