
Page 384 - 《软件学报》2025年第9期
P. 384
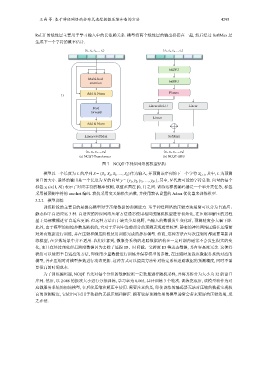
王尚 等: 基于神经网络的分布式追踪数据压缩和查询方法 4295
ReLU 的线性层主要用于学习输入中的长依赖关系. 模型将两个线性层的输出拼接在一起, 然后经过 SoftMax 层
生成下一个字符的概率估计.
{s 1 , s 2 , s 3 ,..., s L } {s 1 , s 2 , s 3 ,..., s L }
biGRU
Multi-head
attention biGRU
1x Add & Norm Flatten
Linear+ReLU Linear
Feed
forward
Linear
Add & Norm
Linear+SoftMax SoftMax
{y 1 , y 2 , y 3 ,..., y N } {y 1 , y 2 , y 3 ,..., y N }
(a) NCQT-Transformer (b) NCQT-GRU
图 7 NCQT 中神经网络的模型结构
模型以一个长度为 L 的序列 S = {S 1 , S 2 , S 3 , …, S L }作为输入, 并预测该序列的下一个字符 S L+1 , 其中, L 为预测
窗口的大小. 最终的输出是一个长度为 N 的向量 y = {y 1 , y 2 , y 3 , …, y N }, 其中, N 代表可能的字符总数. 向量的每个
标签 y i (i∈[1, N]) 表示了对应字符的概率预测, 取值范围在 [0, 1] 之间. 训练这样的编码器是一个单分类任务, 标签
采用被预测字符的 one-hot 编码. 我们采用交叉熵损失函数, 并使用默认设置的 Adam 优化器来训练模型.
3.2.2 模型训练
训练阶段的主要目的是提高模型对于压缩数据的预测能力. 基于神经网络的压缩方法通常可以分为自适应、
静态和半自适应这 3 种. 自适应的神经网络压缩方法通常使用相同的随机模型进行初始化, 在压缩和解压的过程
基于局部数据进行自适应更新. 但这种方法由于缺失全局视野, 当输入的数据发生变化时, 预测精度会大幅下降.
此外, 由于模型的初始参数是随机的, 它对于序列中靠前部分的预测表现通常较差. 静态的神经网络压缩在压缩前
对所有数据进行训练, 并在压缩和解压阶段使用训练完成的静态模型. 然而, 这种方法在每次压缩时都需要重新训
练模型, 在多数场景中并不适用. 我们注意到, 微服务系统的追踪数据结构在一定时期内通常不会发生很大的变
化, 而且在经过预处理后跨度数据因为去除了追踪 ID、时间戳、父跨度 ID 等动态数据, 其内容高度冗余. 这使得
我们可以使用半自适应的方法, 即使用少量数据进行训练并保存模型的参数, 在压缩时加载该微服务系统对应的
模型, 并在压缩时对模型参数进行动态更新. 这种方式可以提高方法针对特定系统追踪数据的预测精度, 同时不需
要很高的时间成本.
为了训练编码器, NCQT 首先对每个分组的数据按照一定数量进行随机采样, 并将其拆分为大小为 32 的窗口
序列. 然后, 以 2 048 的批次大小进行分批训练, 学习率为 0.005, 共计训练 3 个轮次. 训练完成后, 该模型将作为对
应微服务系统的初始模型, 在后续压缩和解压中使用. 需要注意的是, 即使训练的编码器无法对压缩的数据实现较
高的预测精度, 它依旧可以用于数据的无损压缩和解压. 拥有较好预测结果的模型通常会带来更好的压缩效果, 反
之亦然.