
Page 30 - 《软件学报》2025年第9期
P. 30
李奕瑾 等: 基于 RISC-V VLIW 架构的混合指令调度算法 3941
能模型. 相比于其他 RISC-V 模拟器 (如 QEMU [37] 和 Gem5 [38] 等), Spike 的模拟速度和易扩展性最好, 方便进行快
速的原型迭代开发. 本文专注于 VLIW 指令调度的研究, 对于内存等全系统的模拟关注较少, 同时, 现有的模拟器
都不支持 VLIW 的性能模拟, 需要进行进一步的开发. 因此, Spike 更适合作为本文模拟器, 并进一步拓展对 VLIW
功能的支持.
CoreMark [39] 是由 EEMBC 于 2009 年提出的一项基准测试程序, 其代码使用 C 语言编写, 包含以下的算法实
现: 列表处理、矩阵操作、状态机和 CRC 校验等. CoreMark 在嵌入式 CPU 行业中作为普遍公认的性能测试指标,
拥有体积小、方便移植、易于理解、免费并且显示单个数字基准分数的优点, 同时 CoreMark 具有特定的运行和
报告规则, 从而可以避免由于所使用的编译库不同而导致的测试结果难以比较的情况.
3 基于 RISC-V 的 VLIW 架构设计及实现
根据每个指令包的并行指令数是固定还是可变的, 可以将 VLIW 分为定长 VLIW 和变长 VLIW. 在定长
VLIW 架构下, 每个指令包都存储了可并行指令条数的最大值, 当指令包中实际指令数小于最大值时, 需要插入
NOP (空操作) 指令来填充指令包. 由于定长 VLIW 插入过多的 NOP 指令会带来指令数膨胀的问题, 因此本文设
计了基于 RISC-V 的可变长 VLIW 架构, 并基于可变长 VLIW 设计了表示指令包结束的指令编码, 兼容现有
RISC-V32 和 RISC-V64 指令编码.
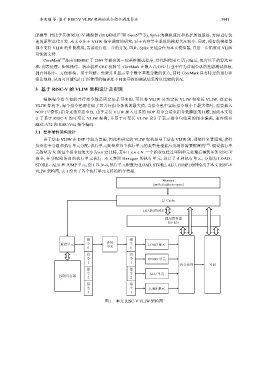
3.1 整体硬件架构设计
由于动态 VLIW 在 DSP 中较为普遍, 因此本研究的 VLIW 架构是基于动态 VLIW 的, 即硬件负责阻塞, 软件
负责指令分组和执行单元分配. 执行单元数量和每个执行单元的类型是根据应用场景需要配置的 [40] . 假设执行单
元数量为 N, 则每个指令包的大小为 n×32 比特, 其中 1 ⩽ n ⩽ N. 一个指令包经过译码单元处理后得到多条 RISC-V
指令, 并分配给各自的执行单元执行. 本文参照 Hexagon 的执行单元, 设计了 4 种执行单元, 分别为 LOAD、
STORE、ALU 和 JUMP 单元, 图 1 以 N=4, 执行单元配置为{LOAD, STORE, ALU, JUMP}为例给出了本文 RISC-V
VLIW 架构图, 表 1 给出了各个执行单元支持的指令类型.
Memory
(unified address space)
L1 Cache
LOAD/STORE
通用寄存器
R0−R31
指 指
取指单元 令 译码 令 LOAD 单元
0 单元 0
指 指
令 令 STORE 单元
1 1
内存访问 写回
指 指
令 令 ALU 单元
控制寄存器
2 2
指 指
令 令 JUMP 单元
3 3
图 1 本文 RISC-V VLIW 架构图