
Page 265 - 《软件学报》2025年第9期
P. 265
4176 软件学报 2025 年第 36 卷第 9 期
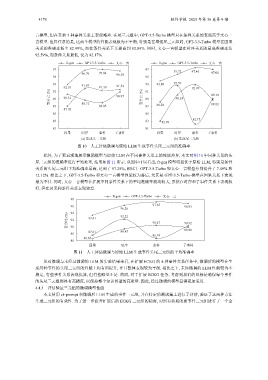
言模型, 但在其他 3 种事件关系上表现略差. 在尾三元组中, GPT-3.5-Turbo 模型只在条件关系的表现高于文心一
言模型. 值得注意的是, 这两个模型的性能表现极为不平衡, 特别是在增强尾三元组时, GPT-3.5-Turbo 模型在因果
关系的准确率低至 82.99%, 而在条件关系下又提高到 92.89%. 同时, 文心一言模型在时序关系的最高准确率达
92.59%, 而条件关系最低, 仅为 82.17%.
ft-gen GPT-3.5-Turbo 文心一言 ft-gen GPT-3.5-Turbo 文心一言
97 97 95.72 97.46
96.79 97.04 96.58 97.08
95 95
92.59
93 91.84 93 93.88
92.93 91.30 91.54 91 92.89
百分比 (%) 89 90.31 90.97 百分比 (%) 89 90.18 89.10
91
87 88.71 88.05 87 88.20 88.82
87.02
85 85
82.17
83 83
82.99
81 81
因果 时序 条件 子事件 因果 时序 条件 子事件
(a) 生成头三元组 (b) 生成尾三元组
图 10 人工评估微调与原始 LLM 生成事件头尾三元组的准确率
此外, 为了更直观地展示微调模型与原始 LLM 在不同事件关系上的性能差异, 本文对图 10 中同种关系的头
尾三元组的准确率进行平均处理, 结果如图 11 所示. 从图中可以看出, ft-gen 模型明显优于原始 LLM, 特别是条件
关系的头尾三元组平均准确率最高, 达到了 97.25%, 相比于 GPT-3.5-Turbo 和文心一言模型分别提升了 7.49% 和
12.12%. 相比之下, GPT-3.5-Turbo 和文心一言模型性能较为落后, 尤其是 GPT-3.5-Turbo 模型在因果关系下表现
最为不佳. 同时, 文心一言模型在扩展不同事件关系下的平均准确率波动较大, 虽然在时序和子事件关系下表现较
好, 但在因果和条件关系表现较差.
ft-gen GPT-3.5-Turbo 文心一言
98
97.25
96 96.83
96.26
94
百分比 (%) 92 93.41 92.22 90.47 90.32
90
89.90
87.61 89.45
88
86.74
86.65
86
因果 时序 条件 子事件
图 11 人工评估微调与原始 LLM 生成事件头尾三元组的平均准确率
从对微调与未经过微调的 LLM 的实验结果来看, 在扩展 ECKG 的 4 种事件关系任务中, 微调后的模型在生
成每种事件的头尾三元组的性能上均有所提升, 并且整体表现较为平衡. 相比之下, 未经微调的 LLM 性能较为不
稳定, 有些事件关系表现优异, 但有些略显不足. 然而, 对于扩展 ECKG 任务, 考虑到我们的目标是确保每个事件
的头尾三元组都具有高精度, 以保持整个知识图谱的高质量. 因此, 经过微调的模型显得更加适用.
4.4.3 评估验证三元组的微调模型性能
本文使用 ek-prompt 和微调后 LLM 生成的事件三元组, 并在特定的测试集上进行了评估, 验证了这两种方法
生成三元组的有效性. 为了进一步提升扩展后的 ECKG 三元组的精度, 对所有获取的新事件三元组进行了一个全