
Page 263 - 《软件学报》2025年第9期
P. 263
4174 软件学报 2025 年第 36 卷第 9 期
(1) GPT-4-Turbo 模型在所有模型中生成的事件三元组准确率最高, 并且每种关系的表现较为稳定, 准确率均
超过 90%. 其中时序和条件关系的尾三元组准确率分别高达 94.92% 和 94.95%.
(2) Claude 3 模型在生成子事件关系的三元组表现较好且均衡, 头尾三元组的准确率都在 90% 以上. 与之相反
的是, 在扩展其他 3 种关系时性能波动较大, 最为明显的是时序和条件关系. 如生成时序关系的头三元组准确率高
达 91.67%, 而尾三元组的准确率仅为 82.24%.
(3) 讯飞星火模型在扩展 4 种事件关系的头尾三元组任务中表现均不平衡, 尤其是在生成条件关系的尾三元
组是准确率较高, 但生成因果关系尾三元组的准确率在所有模型中最低 (71.19%).
(4) 通义千问模型扩展 4 种事件关系的头三元组准确率比尾三元组更为稳定, 在尾事件三元组中, 时序关系的
准确率较高, 达到 93.91%, 但在扩展条件关系时表现略差.
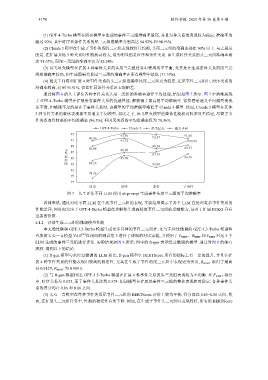
通过将图 6 的人工评估各种事件关系头尾三元组的准确率进行平均处理, 结果如图 7 所示. 图 7 中清晰展现
了 GPT-4-Turbo 模型在扩展所有事件关系的优越性能, 都获得了最高的平均准确率. 紧接着是通义千问模型表现
还不错, 但略微不足的是在子事件关系时, 该模型的平均准确率略低于 Claude 3 模型. 然而, Claude 3 模型在其他
3 种事件关系的整体表现都不及通义千问模型. 相比之下, 讯飞星火模型的整体性能相对较差且不稳定, 尽管子事
件关系取得较高的平均准确率 (86.5%), 但因果关系的平均准确率仅为 78.36%.
GPT-4-Turbo Claude 3 讯飞星火 通义千问
93
93.30 91.60
90.86 92.97
91 91.72 90.90
89 89.08 86.96 88.24 89.37
百分比 (%) 87 84.28 85.90 87.19 86.50
85
83
81 82.04
78.36
79
77
因果 时序 条件 子事件
图 7 人工评估不同 LLM 使用 ek-prompt 生成事件头尾三元组的平均准确率
总体来说, 通过对比不同 LLM 在生成事件三元组的表现, 实验结果揭示了各个 LLM 在处理复杂事件关系的
性能差异, 同时也突出了 GPT-4-Turbo 模型在理解和生成高精度事件三元组的卓越能力, 这对于扩展 ECKG 具有
重要的价值.
4.4.2 评估生成三元组的微调模型性能
本文通过微调 GPT-3.5-Turbo 模型生成更多具体的事件三元组外, 还与未经过微调的 GPT-3.5-Turbo 模型和
百度的文心一言模型 V4.0 [68] 在相同的测试集上进行了详细的对比实验, 并使用了 P BERT 、 R BERT 和 F BERT 对这 3 个
LLM 生成的事件三元组进行评估. 实验结果如图 8 所示, 图中的 ft-gen 表示经过微调的模型. 通过对图 8 的细心
观察, 得到以下的结论.
(1) ft-gen 模型与未经过微调的 LLM 相比, ft-gen 模型在 BERTScore 所有的指标上有一定的提升, 并且在扩
展 4 种事件关系的性能表现出较高的稳定性. 尤其在生成子事件的尾三元组中表现更为突出, R BER 取得了最高
T
分 0.912 9, F BER 为 T 0.909 5.
(2) 与 ft-gen 模型相比, GPT-3.5-Turbo 模型在扩展 4 种事件关系的头三元组表现较为不均衡. 在 F BER 得分
T
中, 时序关系为 0.823, 而子事件关系达到 0.874. 但该模型在扩展尾事件三元组的整体表现相对稳定, 各种事件关
系的得分均在 0.86 和 0.88 之间.
(3) 文心一言模型在每种事件关系尾事件三元组的 BERTScore 评价上较为平衡, 得分都在 0.85–0.88 之间. 然
而, 在扩展头三元组任务中, 性能的稳定性有所下降. 例如, 在生成子事件头三元组时表现较好, 所有的 BERTScore