
Page 96 - 《软件学报》2025年第7期
P. 96
贾昂 等: 面向函数内联场景的二进制到源代码函数相似性检测方法 3017
总的来说, 当使用最佳的基分类器数量 (AdaBoost 为 50, 其余为 300) 时, ECOCCJ48 在所有方法中获得了最
高的 F1 分数. 虽然 RFPCT、RFDTBR 和 EBRJ48 等方法在精确率上更高, 但 ECOCCJ48 在召回率方面表现更优.
总体而言, ECOCCJ48 能够实现 78% 的准确率和 70% 的召回率, 最终能够实现 0.74 的 F1 分数, 领先所有其他
方法.
ECOCCJ48 的卓越性能主要得益于其基于内联规律的分类器链结构设计. 相比于 RFDTBR、EBRJ48、
AdaBoost 等不利用标签依赖关系的方法, ECOCCJ48 通过引入标签依赖关系, 有效地分解了内联规则的学习任务.
高优化选项下的内联规则通常是在低优化选项基础上增加了一些新规则, 而 ECOCCJ48 中从高优化到低优化的
标签依赖关系使其在学习高优化选项时能够利用已从低优化选项中学到的规则. 因此, 在高优化选项下, ECOCCJ48
只需专注于学习新增的规则即可. 相比之下, RFDTBR、EBRJ48 和 AdaBoost 模型在学习高优化选项时缺乏低优
化选项的知识积累, 因此在高优化选项下的内联规则学习中面临较大困难.
此外, 尽管 RFPCT 和 ECCJ48 也在不同优化选项间采用了分类器链模型, 但它们并未精确地利用优化选项之
间的依赖关系, 因而无法达到与 ECOCCJ48 相同的分类性能. 由于内联规则是从低优化到高优化逐步叠加形成的,
采用逆序或无关的顺序构建的分类器链模型无法有效捕捉这一顺序依赖规律.
总体来看, ECOCCJ48 能够发现更多隐藏的内联函数调用, 并能迅速捕捉内联模式.
5.3 时间开销分析
O2NMatcher 在实施过程需要首先训练内联函数调用模型, 然后使用模型进行预测, 最后根据内联标签生成函
数集合. 因此, 本节记录了包括模型训练、模型测试和源代码函数集合生成 3 个不同阶段的运行时间, 进一步评估
了 O2NMatcher 的时间开销.
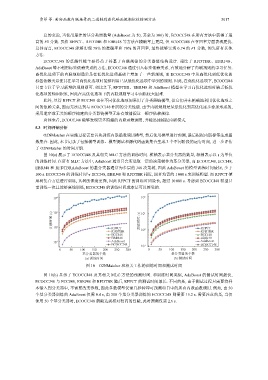
图 10(a) 展示了 ECOCCJ48 及其相关 MLC 方法的训练时间. 横轴表示基分类器的数量, 纵轴表示以 s 为单位
的训练时间. 在所有 MLC 方法中, AdaBoost 通常只会所选取一层的决策树作为基分类器, 而 ECOCCJ48, ECCJ48,
EBRJ48 和 RFDTBRAdaBoost 的基分类器通常为多层的 J48 决策树, 因此 AdaBoost 的模型训练时间最短, 少于
100 s. ECOCCJ48 的训练时间与 ECCJ48, EBRJ48 和 RFDTBR 相近, 四者均需约 1 000 s 来训练模型. 而 RFPCT 使
用树集合方法进行训练, 其树的深度更深, 因此 RFPCT 的训练时间最长, 超过 10 000 s. 考虑到 ECOCCJ48 模型只
需训练一次且能够离线训练, ECOCCJ48 的训练时间成本是可以接受的.
10 4 10 2
训练时间 (s) 10 3 测试时间 (s) 10 1
2
10
RFPCT
RFDTBR 10 0 RFPCT
RFDTBR
ECCJ48 ECCJ48
EBRJ48 EBRJ48
10 1 AdaBoost AdaBoost
ECOCCJ48 −1 ECOCCJ48
10
0 50 100 150 200 250 300 0 50 100 150 200 250 300
基分类器的个数 基分类器的个数
(a) 训练时间 (b) 测试时间
图 10 O2NMatcher 和相关工作的训练时间和测试时间
图 10(b) 显示了 ECOCCJ48 及其相关 MLC 方法的预测时间. 和训练时间类似, AdaBoost 的测试时间最快,
ECOCCJ48 与 ECCJ48, EBRJ48 和 RFDTBR 随后, RFPCT 的测试时间最长. 不同的是, 由于测试过程只需要将样
本输入到分类器中, 不需要改变参数, 因此多数模型仅需几秒钟即可预测项目中的所有内联函数调用. 例如, 由 50
个基分类器训练的 AdaBoost 仅需 0.4 s, 由 300 个基分类器训练的 ECOCCJ48 则需要 15.2 s. 需要注意的是, 当仅
使用 50 个基分类器时, ECOCCJ48 就能达到相对较高的性能, 此时预测仅需 2.6 s.