
Page 503 - 《软件学报》2025年第7期
P. 503
3424 软件学报 2025 年第 36 卷第 7 期
从图 7 中可以看出: (1) RanWI 的效果好于 Random, 这凸显了考虑工人质量和任务重要性的重要意义, 这是
因为考虑工人质量和任务重要性能保留相对高质量的数据. (2) OnlyI 和 OnlyW 的效果均好于 Random 和 RanWI,
这是因为结合效用感知的自适应剪枝能使得保留下来的噪音数据能蕴含较小的噪音量, 这凸显了结合效用感知进
行自适应剪枝的必要性. (3) OnlyW 的效果好于 OnlyI, 这说明在 LDP 的约束下, 工人权重的影响大于工人重要性
的影响, 这是因为在真值发现的过程中, 工人的权重处于主导地位. (4) UAP 的效果一直最好. 这是因为 UAP 具有
上述所有优点.
特别地, 从 UAP 和 NWIE 的对比来看, 不考虑 UAP 的 MAE Change (OnlyW) 要差于不考虑 NWIE 的 MAE
Change (GauImp), 这说明进行剪枝的影响要大于进行权重和重要性估计, 从而与本文的研究动机相呼应.
(6) 合成数据集实验结果
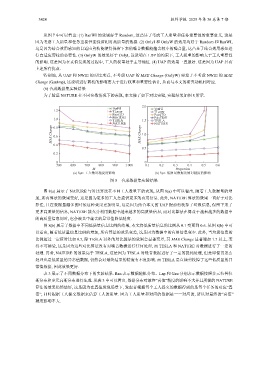
为了验证 NATURE 在不同参数情况下的表现, 本文做了如下对比实验, 实验结果如图 8 所示.
2.0
VarFil VarFil
1.2 TLayer TLayer
PairsTD PairsTD
PrivTDSI PrivTDSI
1.0
TESLA 1.5 TESLA
NATURE NATURE
MAE Change 0.6 MAE Change 1.0
0.8
0.4
0.5
0.2
0 0
500 600 700 800 900 1 000 0.1 0.2 0.3 0.4 0.5 0.6
M Proportion
(a) Syn: 工人数对精度的影响 (b) Syn: 低质量数据比例对精度的影响
图 8 合成数据集实验结果
图 8(a) 展示了 NATURE 与对比算法在不同工人数量下的表现, 从图 8(a) 中可以看出, 随着工人数据量的增
加, 所有算法的效果变好, 这是因为更多的工人会提供更多的有用信息. 此外, NATURE 算法的效果一直好于对比
算法, 且在数据量越多的时候这种效果更加明显, 这是因为结合本文的 UAP 提前剪枝掉了垃圾信息, 保留下来了
更多高质量的信息, NATURE 能充分利用数据中越来越多的高质量信息, 而对比算法在得益于越来越多的数据中
的高质量信息同时, 也会被其中蕴含的异常值降低精度.
图 8(b) 展示了数据中不同低质量信息比例的结果, 本文将低质量信息的比例从 0.1 变更到 0.6. 从图 8(b) 中可
以看出, 随着低质量信息比例的增加, 所有算法的效果变差, 这是因为数据中的有用信息变少. 此外, 当垃圾信息的
比例超过一定值时比如 0.5, 除 TESLA 以外的对比算法的效果会显著变差, 其 MAE Change 显著增加 1.7 以上, 变
得不可接受, 这是因为这些对比算法没有对噪音数据进行任何处理, 而 TESLA 和 NATURE 对数据进行了一定的
处理. 再者, NATURE 的效果高于 TESLA, 这是因为 TESLA 对噪音数据进行了一定的提纯处理, 但是即便再怎么
处理也是低质量的异常值数据, 仍然会对最终结果的精度有不良影响. 而 TESLA 是直接剪枝掉了这些低质量的异
常值数据, 因此效果更好.
表 3 展示了不同数据分布下的实验结果. Ran 表示数据随机分布、Lap 和 Gau 分别表示数据按照多元拉普拉
斯分布和多元高斯分布进行生成. 从表 3 中可以看出, 数据分布对最终“真值”精度的影响不大并且所提的 NATURE
算法的效果仍然最好, 这是因为在真值发现场景下, 发起者根据每个工人提交的数据得到的是每个任务的对应“真
值”, 同时根据工人提交数据来估算工人的质量. 因为工人质量和对应的数据是一一对应的, 所以对最终的“真值”
精度影响不大.