
Page 450 - 《软件学报》2025年第7期
P. 450
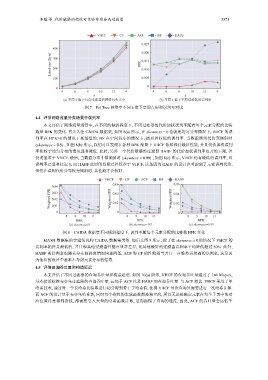
李猛 等: 代价敏感的指纹可变哈希布谷鸟过滤器 3371
VHCF CF ACF BF HABF
0.025
400
0.020
Label size (Byte) 200 FPR 0.015
300
0.010
100 0.005
0
0
4 6 8 10 12 4 4 6 8 10 12 4
k k
(a) 不同 k ᆴ下包含过滤器的网络包头大小 (b) 不同 k ᆴ下不同过滤器的误判率
图 7 Fat Tree 网络中不同 k 值下空间占用和误判率对比
4.4 评估网络流量分类场景中误判率
本文评估了网络流量场景中, 在不同的倾斜程度下, 不同过滤器的代价加权误判率随着每个元素分配的比特
数量 BPK 的变化. 首先关注 CAIDA 数据集, 如图 8(a) 所示, 在 skewness = 0 也就是均匀分布情况下, VHCF 的误
判率在 BPK>8 的情况下是最低的. BF 在空间较小的情况下, 拥有着较低的误判率. 当数据误判代价变倾斜时
(skewness = 0.5) , 如图 8(b) 所示, 我们可以发现在各种 BPK 配置下 VHCF 依然保持最好性能, 并且代价加权误判
率相较于均匀分布的情况显著降低. 此时, 另外一个代价敏感的过滤器 HABF 的代价加权误判率也开始下降, 但
仍明显差于 VHCF. 最后, 当数据分布非常倾斜时 (skewness = 0.99) , 如图 8(c) 所示, VHCF 仍有最低的误判率, 且
误判率已显著接近 0, 而 HABF 此时的性能已经仅次于 VHCF, 这是因为 HABF 的设计也考虑到了元素误判代价,
但仅在误判代价分布较为倾斜时, 其性能才会较好.
VHCF CF ACF BF HABF
0.06 0.06
0.04
Weighted FPR 0.03 Weighted FPR 0.04 Weighted FPR 0.04
0.02
0.02
0.02
0.01
0 0 0
8 9 10 11 8 9 10 11 8 9 10 11
BPK BPK BPK
(a) skewness=0 (b) skewness=0.5 (c) skewness=0.99
图 8 CAIDA 数据集不同倾斜程度下, 误判率随每个元素分配的比特数 BPK 变化
MAWI 数据集的实验情况和 CAIDA 数据集类似. 如后文图 9 所示, 除了在 skewness = 0 的情况下 VHCF 的
误判率始终是最低的, 并且和其他过滤器性能有显著差异, 比其他最好的过滤器误判率平均降低超过 50%. 此外,
HABF 的误判率也随着分布倾斜度增加快速降低. ACF 和 CF 的性能相当并且一直维持着较高的误判率, 这是因
为他们的设计中基本不考虑元素分布的信息.
4.5 评估查询吞吐量和构造延迟
本文评估了不同过滤器的查询吞吐量和构造延迟. 如图 10(a) 所示, VHCF 的查询吞吐量超过了 100 Mops/s,
基本接近标准布谷鸟过滤器的查询吞吐量, 远高于 ACF 以及 HABF 的查询吞吐量. 与 ACF 相比, VHCF 采用了单
哈希技术, 通过对一个长哈希比特串进行切分得到若干子哈希值, 使得 VHCF 每次查询只需要进行一次哈希计算.
而 ACF 的设计基于布谷鸟哈希表, 同时每个指纹的生成函数都是独立的, 所以无论是确定元素在每个子表中的对
应位置还是得到指纹, 都需要引入大量的哈希函数计算, 进而拖慢了查询的速度. 因此, ACF 的吞吐量会远低于