
Page 449 - 《软件学报》2025年第7期
P. 449
3370 软件学报 2025 年第 36 卷第 7 期
集进行测试. 这个数据集包含了从 WIDE 骨干网采集的网络流量信息, 本文以源 IP 目标 IP 作为元素内容, 并从中
选取了包含 1 千万条网络流量的子集进行测试. 更为具体的信息, 本文列在了表 2 中. 此外, 在测试 CAIDA
和 MAWI 数据集时, 本文主要关注数据误判代价分布倾斜情况下的不同过滤器的代价加权误判率. 这里为了更好
地测试不同的倾斜分布, 本文使用 Zipf 分布, 其通过参数 skewness 来衡量倾斜性, 值越大分布越倾斜, 即更少的元
素占据了更大的比例.
表 2 实验数据集信息
数据集 不同元素个数 数据类型
CAIDA 约7百万 源目标IP地址
MAWI 约1千万 源目标IP地址
● 参数设置. 为了确保不同算法的公平比较, 本文在实验评估过程中要求所有被比较的算法尽可能使用相同
的内存空间. 为了衡量不同过滤器使用的空间大小, 本文使用指标 BPK (bits-per-key), 即每个元素使用的比特数
目. 在满足这一要求的基础上, 本文根据每个测试算法的默认参数设置来设定各个算法的参数.
4.2 评估参数影响分析
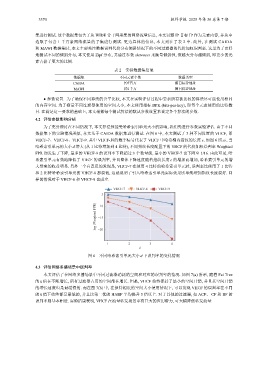
为了充分探讨在不同情况下, 本文算法性能受哈希索引单元大小的影响, 我们先进行参数实验评估. 由于不同
数据集下的实验情况类似, 本文基于 CAIDA 数据集进行测试. 在图 6 中, 本文测试了 3 种不同设置的 VHCF, 即
VHCF-7、VHCF-8、VHCF-9. 其中 VHCF-后的数字标号代表了 VHCF 中哈希桶内指纹的长度 e. 如图 6 所示, 当
哈希索引单元的大小 d 增大 (从 1 比特增加到 4 比特), 不同指纹长度配置下的 VHCF 的代价加权误判率 Weighted
FPR 均发生了下降, 最多的 VHCF-9 的误判率下降超过 3 个数量级, 最小的 VHCF-7 也下降至 1/16. 由此可见, 哈
希索引单元有效地降低了 VHCF 的误判率, 并且整体下降速度随着指纹长度 e 的增加而增加, 哈希索引单元的增
大带来的收益明显. 另外一个有意思的发现是, VHCF-7 在使用 4 比特的哈希索引单元时, 误判率比使用了 1 比特
和 2 比特哈希索引单元的 VHCF-8 都要低, 这就说明了引入哈希索引单元实际效果比单纯增加指纹长度要好. 同
样的情况对于 VHCF-8 和 VHCF-9 也成立.
VHCF-7 VHCF-8 VHCF-9
−5
log (Weighted FPR) −10
−15
−20
1 2 3 4
d
d 下误判率的变化情况
图 6 不同哈希索引单元大小
4.3 评估网络多播场景中误判率
本文评估了在网络多播场景中不同过滤器消耗的空间和对应的误判率的情况. 如图 7(a) 所示, 随着 Fat Tree
的 k 值在不断增长, 所有过滤器占用的空间都在增长. 但是, VHCF 始终保持了最小的空间开销, 并且其空间开销
的增长速度也是最缓慢的. 而在图 7(b) 中, 在保持相近的空间大小使用情况下, 可以发现 VHCF 的误判率在不同
k 值下始终都是最低的, 并且比第二优的 HABF 平均提升 5 倍以上. 对于其他的过滤器, 如 ACF、 CF 和 BF 的
的
误判率则基本相近. 实验结果表明, VHCF 在流量转发场景中有巨大的应用潜力, 可大幅降低转发流量.