
Page 14 - 《软件学报》2025年第7期
P. 14
王树兰 等: eDPRF: 高效的差分隐私随机森林训练算法 2935
ε=0.18
A
ε=0.27 ε=0.82
B C
D ε=0.55 E ε=0.55
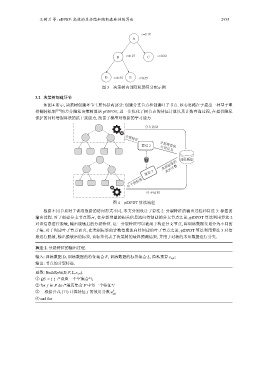
图 3 决策树内部隐私预算分配示例
3.2 决策树创建环节
如图 4 所示, 决策树创建环节主要包括两部分: 创建分支节点和创建叶子节点. 核心思路在于提出一种基于重
排翻转机制 [12] 的差分隐私决策树算法 pfDPDT, 进一步优化了树节点的特征计算以及计数查询过程, 在提供隐私
保护的同时增强算法的抗干扰能力, 改善了模型对数据的学习能力.
分支访问
分裂特征
算法 2 分裂增益的
计算信息
类别标签的 训练数据
真实计数
算法 3
叶子的标签
叶子访问
图 4 pfDPDT 算法流程
根据不同节点对于训练数据的访问形式不同, 本文分别设计了算法 2: 分裂特征的输出过程和算法 3: 标签的
输出过程. 对于创建分支节点而言, 在分裂增益的相关信息流向待创建的分支节点之前, pfDPDT 算法利用算法 2
对该信息进行脱敏, 输出脱敏后的分裂特征. 这一分裂特征可以被用于构建分支节点, 将训练数据集划分为不同的
子集. 对于创建叶子节点而言, 在类别标签的计数信息流向待创建的叶子节点之前, pfDPDT 算法利用算法 3 对信
息进行脱敏, 输出脱敏后的标签, 该标签代表了决策树的最终预测结果, 并用于对新的未知数据进行分类.
算法 2. 分裂特征的输出过程.
F
输入: 训练数据 D, 训练数据的特征集合 , 训练数据的标签集合 L, 隐私预算 ε spl ;
输出: 节点的分裂特征.
函数: BuildSplit(D,F,L,ε spl ).
① QS = { } /*设置一个空集合*/;
② for f in do /*遍历集合 F 中每一个特征*/
F
③ 根据公式 (11) 计算特征 f 的效用分数 u f
spl
④ end for