
Page 313 - 《软件学报》2025年第4期
P. 313
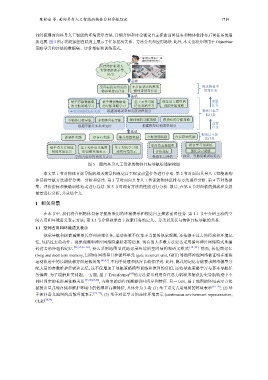
陈铂垒 等: 面向具身人工智能的物体目标导航综述 1719
同时梳理面向具身人工智能的环境表示方法, 详细介绍和讨论视觉自主探索前置任务和物体重排布后置任务的最
新进展. 图 5 所示的框架图自底向上展示了任务层次关系、方法分类和应用场景. 此外, 本文也将介绍用于 ObjectNav
策略学习和评估的数据集、评价指标和训练范式.
请到客厅帮我拿一杯
咖啡并整理好客厅...
医疗陪护机器人、
智能家庭助手等
应用.
基础
受目标状态约束的 无目标状态约束的 视觉物体重
物体重排布任务 物体重排布任务 排布任务
基础
基于有限数据集 基于增强数据集 基于元学习的 视觉语言模型增 前置
的导航策略学习 的导航策略学习 泛化策略学习 强的导航策略 任务
表示时间先后关系 根据策略类型和发展进程划分 物体目标导
航任务
(long and short term memory, LSTM) 网络和门控循环单元
单物体目标导航 多物体目标导航 端到端的导航策略 模块化的导航策略
前置
根据导航任务类型划分 根据模型结构类型划分 任务
基础
视觉自主探
新颖性奖励 好奇心奖励 覆盖范围奖励 占据预期奖励 内在影响奖励 索任务
室内仿真数据集 模仿学习预训练
基于语义占用地 基于拓扑语义地图 基于对比学习的
图的环境表示 的离散环境表示 连续环境表示 评价指标 强化学习调优
空间占用和环境语义表示 数据集与评估 探索、导航策略训练范式
图 5 面向具身人工智能的物体目标导航综述架构图
本文第 1 节对物体目标导航的相关背景和视觉自主探索前置任务进行介绍. 第 2 节对面向具身人工智能的物
体目标导航方法进行分类、分析和总结. 第 3 节对面向具身人工智能的物体重排布方法进行分析. 第 4 节对数据
集、评价指标和策略训练范式进行总结. 第 5 节对现有方法的性能进行分析. 最后, 在第 6 节对面临的挑战和发展
前景进行分析, 并总结全文.
1 相关背景
在本节中, 我们将介绍物体目标导航所采用的环境表示和视觉自主探索前置任务. 第 1.1 节中介绍主流的空
间占用和环境语义表示方法; 第 1.2 节介绍视觉自主探索任务的定义、分类以及其与物体目标导航的关系.
1.1 空间占用和环境语义表示
视觉导航和探索通常是长序列决策任务, 运动决策不仅基于当前的视觉观测, 还依赖于过去的经验和环境记
忆, 包括过去的动作、视觉观测和神经网络隐藏状态等信息. 现有的大多数方法要么采用循环神经网络隐式地编
码过去的经验和记忆 [32,34,36−38] , 要么采用地图显式地记录环境的空间结构和语义模式 [18−23] . 然而, 长短期记忆
(gate recurrent unit, GRU) 等循环神经网络被证明在捕获
运动轨迹中的长期依赖方面是低效的 [62,63] , 不利于处理和执行长动作序列. 此外, 隐式的记忆存储要求网络模型分
配大量的参数维护经验和记忆, 这不仅增加了导航策略模型训练和推理的负担, 还将导致策略学习与基本导航任
务偏离. 为了缓解此类问题, 一方面, 基于 Transformer [64] 的方法提出利用自注意力机制来捕获历史导航轨迹中不
同时间步的长距离依赖关系 [35,48,65,66] , 为将来的动作预测提供时间序列特征. 另一方面, 基于地图的环境表示方法
被提出显式地存储和维护环境中的低维和高维特征, 具体分为 3 类: (1) 基于语义占用地图的环境表示 [67−70] ; (2) 基
于拓扑语义地图的离散环境表示 [71−77] ; (3) 基于对比学习的连续环境表示 (continuous environment representation,
CER) [78,79] .