
Page 249 - 《软件学报》2025年第4期
P. 249
李梓童 等: 机器遗忘综述 1655
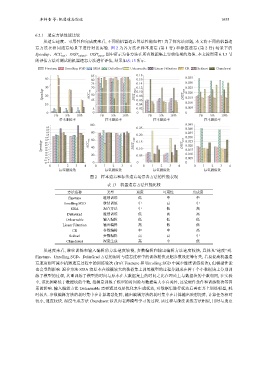
6.2.1 遗忘方法性能比较
从遗忘速度、可用性和完成度来看, 不同的机器遗忘算法性能如何? 为了探究该问题, 本文将不同的机器遗
忘方法在相同遗忘场景下进行对比实验. 图 2 为各方法在样本遗忘 (第 1 行) 和标签遗忘 (第 2 行) 场景下的
Speedup、ACC test 、DIST output 、DIST para , 图中所示为各方法在所有数据集上实验结果的均值. 本文按照第 6.1.5 节
的评估方法对测试的机器遗忘方法进行评估, 结果如表 13 所示.
Finetune Unrolling SGD SISA DeltaGrad Unlearnable Linear Filtration CR Sekhari Chundawat
85 0.18
60 80 0.16 0.035
75 0.14 0.030
70
Speedup 30 ACC test 50 DIST output 0.12 DIST para 0.025
0.10
0.020
20
0.08
0.015
45
0.06
0.010
10 0.04
5 0.02 0.005
0 0 0 0
1% 5% 10% 1% 5% 10% 1% 5% 10% 1% 5% 10%
样本删除率 样本删除率 样本删除率 样本删除率
100 0.045
10 4 0.25 0.040
10 3
10 2 80 0.035
10 1 0.20
10 -1
10 -2 -3 ACC test 60 0.15 DIST para 0.030
0.025
Speedup 10 -4 -5 -6 40 DIST output 0.10 0.020
10
10
0.015
10
10 -7 0.010
10 -8 20 0.05
10 -9 0.005
10 -10
10 -11 0 0 0
0 1 2 3 4 0 1 2 3 4 0 1 2 3 4 0 1 2 3 4
标签删除数 标签删除数 标签删除数 标签删除数
图 2 样本遗忘和标签遗忘场景各方法的性能表现
表 13 机器遗忘方法性能比较
(如在
方法名称 类型 速度 可用性 完成度
Finetune 继续训练 低 中 中
Unrolling SGD 继续训练 中 高 中
SISA 混合方法 中 低 高
DeltaGrad 继续训练 低 高 高
Unlearnable 输入编辑 低 低 低
Linear Filtration 输出编辑 高 低 低
CR 参数编辑 中 中 高
Sekhari 参数编辑 高 高 中
Chundawat 深度生成 高 中 低
从速度来看, 继续训练和输入编辑的方法速度较慢, 参数编辑和输出编辑方法速度较快, 具体见“速度”列.
Finetune、Unrolling SGD、DeltaGrad 方法的用时与遗忘过程中的训练轮次及超参数设定等有关, 若要提高机器遗
忘速度则可减少机器遗忘过程中的训练轮次 Finetune 和 Unrolling SGD 中减少继续训练轮次), 但模型性能
也会受到影响. 混合方法 SISA 将原本在规模较大的数据集上训练模型的过程分割成在若干个小数据块上分别训
练子模型的过程, 其重训练子模型的时间与原本在大数据集上的时间之比在理论上与数据块的个数相同, 在实验
中, 该比例略低于数据块的个数, 推测是训练子模型的时间除与数据集大小有关外, 还受硬件条件和训练轮次等因
素的影响. 输入编辑方法 Unlearnable 需要通过双层优化来生成扰动, 对数据集进行扰动后再在其上训练模型, 耗
时较久. 参数编辑方法的耗时集中在计算海瑟矩阵, 输出编辑方法的耗时集中在计算输出映射矩阵, 计算任务相对
较小, 速度较快. 深度生成方法 Chundawat 涉及向老师模型学习的过程. 该过程与继续训练方法相似, 用时与遗忘