
Page 489 - 《软件学报》2024年第6期
P. 489
张浩南 等: 高清几何缓存多尺度特征融合的渲染超分方法 3065
这使得图像重建过程能获得更多的高频特征, 对高清内容图像的细节内容进行合理复原, 提升了超分结果的保
真度.
另外地, 为了进一步验证本文所提的网络架构相对于以往网络的有效性, 我们将所使用的几何缓存进行了删
减, 只保留场景深度, 从而与 NSRR 中所使用的几何缓存保持一致. 表 5 给出了场景深度的消融实验结果, 其中+sd
表示作为输入的几何缓存仅保留场景深度, 超分规模均为 4×4, 从表 5 的指标对比上可以看出, 该模型表现优于第
[9]
4.2 节中 NSRR 的方法, 说明即使在不使用历史信息的情况下, 我们的方法仍可以用多层次融合机制等特点获得
更优秀的画面表现, 而且使用更多的几何缓存信息可以进一步提升超分画面质量.
表 5 Medieval Docks 场景下移除场景深度的性能指标对比
指标 +sd NSRR Ours
PSNR (dB) 22.40 20.79 25.37
SSIM 0.730 5 0.700 6 0.870 5
4.4.3 整体网络结构
12
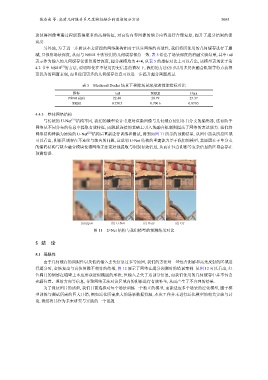
与传统的 U-Net [21] 结构不同, 我们的模型设计考虑对渲染图像与几何缓存使用各自分支的编码器, 这有助于
网络从不同分布的信息中提取有效特征, 而跳跃连接的基础上引入的融合机制则提高了网络的表达能力. 我们将
网络结构替换为原始的 U-Net [21] 结构后重新进行训练和测试, 得到如图 11 所示的预测结果. 从图中箭头所指区域
可以看出, 阴影区域存在不连续与缺失的问题, 这说明 U-Net 结构的重建能力差于我们的模型, 其原因在于单分支
的编码结构与缺少融合模块使得网络无法更好地提取与识别有效信息, 从而在包含阴影等复杂信息的区域会存在
预测错误.
(a) Input (b) U-Net (c) Ours (d) GT
图 11 U-Net 结构与我们模型的预测结果对比
5 结 论
5.1 局限性
由于几何缓存的局限性以及低清输入丢失信息过多等原因, 我们的方法对一些包含阴影和高光反射的区域进
行超分时, 会恢复出与真值图像不相符的结果, 图 展示了网络在超分预测时的错误案例. 从图 12 可以看出, 红
色阀门的倒影在墙壁上本应形成近似椭圆的形状, 但输入丢失了这部分信息, 而我们使用的几何缓存中并不包含
光源位置、照射方向等信息, 导致网络无法对该区域内的阴影进行有效补全, 从而产生了不合理的结果.
为了保证图片的质量, 我们目前选择对每个场景训练一个独立的模型, 而能适应多个场景的泛化模型, 囿于模
型训练与测试所需的巨大开销, 例如泛化所需庞大的场景数据资源, 本次工作并未进行泛化模型的相关实验与讨
论, 我们将其作为未来研究与实践的一个话题.