
Page 255 - 《软件学报》2024年第6期
P. 255
向毅 等: 基于多样性 SAT 求解器和新颖性搜索的软件产品线测试 2831
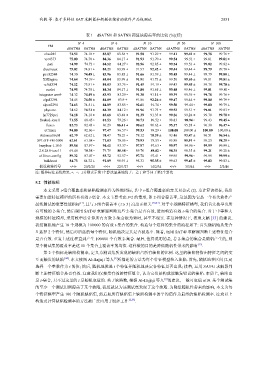
表 1 dSATNS 和 SATNS 两算法覆盖率的比较 (%)(续)
N=4 N=6 N=10 N=50 N=100
FM
dSATNS SATNS dSATNS SATNS dSATNS SATNS dSATNS SATNS dSATNS SATNS
ebsa285 74.52 74.18 ± 83.87 83.58 ± 91.58 91.29 ± 99.41 99.42 ± 99.78 99.76 ±
vrc4373 75.00 74.70 ± 84.36 84.17 ± 91.93 91.70 ± 99.54 99.51 • 99.81 99.81 ±
pati 74.99 74.73 • 84.52 84.27 • 92.96 92.85 ± 99.54 99.53 ± 99.82 99.82 ±
dreamcast 75.02 74.81 ± 84.21 83.99 ± 91.97 92.42 ± 99.44 99.44 ± 99.79 99.78 ±
pc i82544 74.30 74.48 ± 83.96 83.85 ± 91.66 91.39 ± 99.45 99.44 ± 99.79 99.80 ±
XSEngine 74.64 74.39 • 84.04 83.99 ± 91.91 91.73 ± 99.50 99.50 ± 99.81 99.81 ±
refidt334 74.12 73.91 ± 84.03 83.75 • 91.45 91.19 • 99.43 99.45 ± 99.78 99.78 ±
ocelot 74.95 74.70 ± 84.34 84.17 ± 91.80 91.65 ± 99.48 99.46 ± 99.81 99.80 •
integrator arm9 74.32 74.49 ± 83.93 83.29 • 91.30 91.14 ± 99.39 99.39 ± 99.78 99.76 ±
olpcl2294 74.45 74.50 ± 84.09 83.9 ± 91.86 92.26 ± 99.47 99.44 ± 99.80 99.79 ±
olpce2294 74.63 74.51 ± 84.09 83.85 • 92.61 91.76 • 99.50 99.44 • 99.80 99.79 ±
phycore. 74.62 74.72 ± 84.39 84.12 • 91.96 91.73 ± 99.53 99.51 ± 99.81 99.81 ±
hs7729pci 74.18 74.18 ± 83.68 83.48 ± 91.39 91.33 ± 99.26 99.24 ± 99.70 99.70 ±
[2]
freebsd-icse11 71.55 68.45 • 81.53 79.26 • 90.73 89.52 • 98.83 98.94 ◦ 99.43 99.45 ±
fiasco 82.73 82.43 • 86.29 86.41 ± 90.62 90.62 ± 95.37 95.28 ± 96.38 96.47 ±
uClinux 94.00 92.06 • 97.47 96.57 • 99.53 99.29 • 100.00 100.00 ± 100.00 100.00 ±
Automotive01 62.79 62.62 ± 70.47 70.21 • 78.32 78.39 ± 93.46 93.47 ± 96.51 96.54 ±
SPLOT-FM-5000 62.61 61.08 • 71.03 70.05 • 79.93 79.53 • 95.89 95.91 ± 98.23 98.25 ±
busybox-1.18.0 89.84 87.97 • 94.41 93.37 • 97.97 97.63 • 99.97 99.96 • 99.99 99.99 ±
2.6.28.6-icse11 69.46 70.35 ◦ 79.79 80.58 ◦ 89.70 89.82 ◦ 98.35 98.35 ± 99.21 99.20 ±
uClinux-config 89.32 87.07 • 93.72 92.57 • 97.71 97.41 • 99.95 99.96 ◦ 99.99 99.99 ±
buildroot 84.73 84.72 ± 91.09 90.93 ± 95.33 95.35 ± 99.63 99.65 ± 99.83 99.83 ±
假设检验符号 •/◦/± 20/2/28 •/◦/± 22/1/27 •/◦/± 14/2/34 •/◦/± 3/3/44 •/◦/± 2/2/46
注: 粗体标注最优结果, •、◦、±分别表示第1个算法显著地优于、差于和等同于第2个算法
5.2 性能指标
本文采用 t-组合覆盖率和缺陷检测率作为性能指标, 其中 t-组合覆盖率的定义见公式 (2). 为计算该指标, 我们
需要知道特征模型的所有有效 t-集合. 本文主要考虑 t=2 的情形, 即 2-组合覆盖率, 这是因为它是一个有关软件产
品线测试的重要性能指标 [3] , 且与 t-组合覆盖率 ( t ⩾ 3 ) 高度正相关 [34,43] . 对于小规模特征模型, 我们首先枚举出所
有可能的 2-集合, 然后调用 SAT4J 求解器判断这些 2-集合是否有效, 进而构造有效 t-集合的集合. 对于中等和大
规模的特征模型, 采用枚举法计算所有有效 2-集合极为费时, 甚至不现实. 在这种情况下, 按照文献 [33] 的建议,
我们随机地产生 10 个规模为 100 000 的有效 t-集合的集合. 构造每个这样的集合的流程如下: 首先随机地从集合
X 选择 2 个特征, 然后对所选的每个特征, 随机地决定其是否被选中. 接着, 运用 SAT4J 求解器判断上述特征组合
是否有效. 重复上述过程直到产生 100 000 个有效 2-集合. 最后, 值得说明的是, 若 2-集合的集合是随机产生的, 则
某个测试集的覆盖率是这 10 个集合上覆盖率的均值. 这样做的目的是降低随机性带来的影响 [33] .
第 2 个指标是缺陷检测率, 定义为测试集所发现的缺陷占所有缺陷的比例. 这里的缺陷特指由特征之间的交
互而触发的缺陷 [44] . 本文按照 Al-Hajjaji 等人 所描述的方法为每个特征模型植入缺陷. 首先, 随机地在区间 [2,6]
选择一个整数作为 t 的值; 然后, 随机地挑选 t 个特征并随机地决定各特征是否出现; 接着, 运用 SAT4J 求解器判
断上述特征组合是否有效. 注意我们仅接受有效的特征组合, 认为它们是构成能触发错误的缺陷. 本质上, 缺陷也
是 t-集合, 只不过这里的 t 是随机取值的. 关于缺陷数, 根据 Al-Hajjaji 等人 [2] 的建议, 一般可取值 n/10. 某个测试集
的至少一个测试用例覆盖了某个缺陷, 我们就认为该测试集发现了这个缺陷. 为降低随机性带来的影响, 本文为每
个特征模型产生 100 个随机缺陷集, 然后取所有缺陷集上缺陷检测率的平均值作为最终的缺陷检测率. 注意以上
构造及计算缺陷检测率的方法被广泛应用于既往工作 [2,33] .