
Page 516 - 《软件学报》2024年第4期
P. 516
2094 软件学报 2024 年第 35 卷第 4 期
sys tlsf tc je hd tbb sn mi tlsfcc hslab wfslab
1 000 1 000
请求延迟 (μs) 600 请求延迟 (μs) 600
800
800
400
400
200 200
0 0
90.0 99.0 99.9 99.99 99.999 99.999 9 90.0 99.0 99.9 99.99 99.999 99.999 9
malloc 请求延迟百分位 malloc 请求延迟百分位
(a) x86/64 平台 (b) aarch64 平台
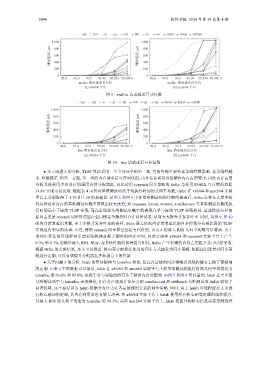
图 9 malloc 请求延迟百分位数
sys tlsf tc je hd tbb sn mi tlsfcc hslab wfslab
1 000 1 000
请求延迟 (μs) 600 请求延迟 (μs) 600
800
800
400
400
200 200
0 0
90.0 99.0 99.9 99.99 99.999 99.999 9 90.0 99.0 99.9 99.99 99.999 99.999 9
free 请求延迟百分位 free 请求延迟百分位
(a) x86/64 平台 (b) aarch64 平台
图 10 free 请求延迟百分位数
● 关于问题 2 的分析. TLSF 算法采用一个全局共享的单一堆, 它的性能主要受竞争线程数影响, 竞争线程越
多, 性能越差. 但另一方面, 单一堆的内存请求是可序列化的, 由并发访问导致的额外内存占用较少, 因此内存占用
也较其他采用多堆设计的通用内存分配器低. 对比使用 ccsynch 同步策略的 tlsfcc 与使用 POSIX 互斥锁的原始
TLSF 实现可以发现: 根据表 4 中所有基准测试项的平均执行时间的几何平均数, tlsfcc 在 x86/64 和 aarch64 实验
平台上分别取得了 1.76 和 1.59 的加速比. 从图 5 和图 6 中各基准测试项的详细结果来看, tlsfcc 在存在大量多线
程并发请求内存的基准测试负载中表现出较大优势, 如 cxqueue, larson, mstress, xmalloc-test 等基准测试负载的执
行时间远小于原始 TLSF 实现, 而在单线程基准测试负载中的表现几乎与原始 TLSF 实现相同. 造成性能差异的
原因主要是 ccsynch 同步算法能在全局锁竞争激烈时合并同步请求, 从而大大提升并发吞吐率. 同时, 从图 9, 图 10
的内存请求延迟来看, 由于多核并发吞吐率的提升, tlsfcc 最差情况内存请求延迟的百分位数分布相比原始 TLSF
实现也有明显的改善. 不过, 使用 ccsynch 同步算法也是有代价的, 由表 4 的最大 RSS 几何平均数可以看到: 由于
该同步算法的每线程同步请求结构体占据了额外的内存空间, 因此分别在 x86/64 和 aarch64 实验平台上产生
9.0% 和 0.7% 的额外最大 RSS. 然而, 与多核性能的显著提升相比, tlsfcc 产生轻微的内存占用提升是可以接受的.
根据 tlsfcc 的实验结果, 本文可以得出: 将内存分配算法使用的同步方式抽象为同步策略, 依据应用场景对同步策
略进行定制, 可以有效提升分配器在多核场景下的性能.
● 关于问题 3 的分析. hslab 的整体架构与 tcmalloc 相似, 但在各层级的同步策略以及线程缓存上做了更精细
的定制. 由表 4 中的数据可以得出, hslab 在 x86/64 和 aarch64 实验平台上的基准测试的执行时间几何平均值仅为
tcmalloc 的 69.6% 和 85.0%, 也优于参与实验的所有基于锁的内存分配器. 由图 5 和图 6 可以看到, hslab 在大多数
基准测试项中与 tcmalloc 表现接近, 但在存在较高并发压力的 xmalloc-test 和 sh8bench 基准测试项, hslab 取得了
显著优势, 这主要是因为 hslab 依据并发压力在各层级使用合适的同步策略. 同时, 由于 hslab 对线程缓存大小进
行核心感知的定制, 其内存利用率也有较大改善. 在 x86/64 实验平台上 hslab 使用所有核心相等份额的线程缓存,
其最大 RSS 的几何平均值为 tcmalloc 的 94.5%; 而在 aarch64 实验平台上, hslab 依据异构核心信息动态定制线程