
Page 515 - 《软件学报》2024年第4期
P. 515
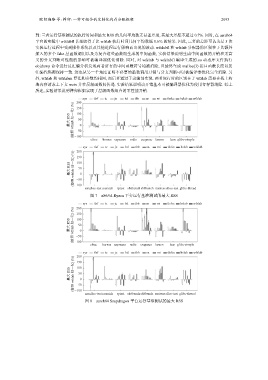
欧阳湘臻 等: 榫卯: 一种可组合的定制化内存分配框架 2093
到: 三者运行基准测试的执行时间和最大 RSS 的几何平均数无显著差别, 其最大差距不超过 0.7%. 同时, 在 aarch64
平台的实验中 wfslabfl 甚至取得了比 wfslab 执行时间几何平均数低 0.6% 的结果. 因此, 三者的差距可认为是 5 次
实验运行过程中受到操作系统以及其他进程运行影响而出现的波动. wfslabfl 和 wfslab 分配器的区别在于其额外
插入的多个 fake 层函数调用以及为复合这些函数而生成的中间函数, 实验结果说明生成中间函数的开销和无意
义的分支判断对性能的影响可被编译器优化消除. 同时, 对 wfslab 与 wfslabfl 编译生成的.so 动态库文件执行
objdump 命令进行反汇编分析发现两者所有的中间函数符号均被消除, 且最终生成 malloc(3) 接口函数长度以及
汇编代码都保持一致. 这也从另一个角度证明不必要的函数调用开销与分支判断可以被编译器优化完全消除. 另
外, wfslab 和 wfslabm 算法和参数均相同, 而后者通过手动编写实现. 两者运行时的区别在于 wfslab 需要在栈上构
造内存请求上下文 mctx 并在层级函数间传递. 实验结果说明该开销基本可被编译器优化为使用寄存器消除. 综上
所述, 实验结果说明榫卯框架实现了层级函数组合的零性能开销.
sys tlsf tc je hd tbb sn mi tlsfcc hslab wfslab
200
150
最大 RSS (按照 wfslab 归一化) (%) 100 0
50
−50
−100
cfrac barnes espresso redis cxqueue larson lean glibc-simple
sys tlsf tc je hd tbb sn mi tlsfcc hslab wfslab
200
150
最大 RSS (按照 wfslab 归一化) (%) 100 0
50
−50
−100
xmalloc-test cscratch rptest sh6benchsh8bench mstress alloc-test glibc-thread
图 7 x86/64 Ryzen 平台运行基准测试的最大 RSS
sys tlsf tc je hd tbb sn mi tlsfcc hslab wfslab
200
150
最大 RSS (按照 wfslab 归一化) (%) 100 0
50
−50
−100
cfrac barnes espresso redis cxqueue larson lean glibc-simple
sys tlsf tc je hd tbb sn mi tlsfcc hslab wfslab
200
150
最大 RSS (按照 wfslab 归一化) (%) 100 0
50
−50
−100
xmalloc-testcscratch rptest sh6benchsh8bench mstress alloc-test glibc-thread
图 8 aarch64 Snapdragon 平台运行基准测试的最大 RSS