
Page 35 - 《软件学报》2024年第4期
P. 35
杨宏宇 等: 基于多模态对比学习的代码表征增强预训练方法 1613
表 7 各模型预训练使用的资源统计
模型 输入长度 显卡资源 批量大小 时间(h) 训练步数(k)
CodeBERT 512 16 块 NVIDIA Tesla V100 2 048 6 100
GraphCodeBERT 640 32 块 NVIDIA Tesla V100 1 024 83 200
SynCoBERT 512 8 块 NVIDIA Tesla V100 128 80 110
UniXcoder 1 024 64 块 NVIDIA Tesla V100 1 024 192 800
REcomp(C/G/U) 300 3 块 NVIDIA Tesla V100 64/60/48 7/5.5/5.25 28/22/21
3.4.4 融合算法有效性分析
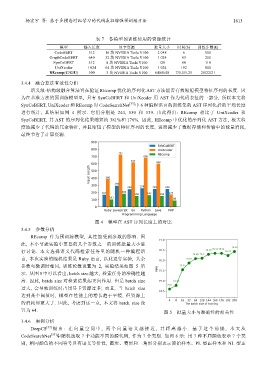
语义级-结构级融合算法旨在验证 REcomp 优化的序列化 AST 方法能否有效缩短模型特征序列的长度. 因
为在基准方法的预训练模型里, 只有 SynCoBERT 和 UniXcoder 用 AST 作为代码表征的一部分, 所以本文将
SynCoBERT, UniXcoder 和 REcomp 对 CodeSearchNet [33] 中 6 种编程语言的训练集的 AST 序列化后的平均长度
进行统计, 其结果如图 4 所示. 它们分别是 244, 530 和 139. 由此得出: REcomp 相比于 UniXcoder 和
SynCoBERT, 其 AST 的序列化结果缩短约 381%和 176%. 因此, REcomp 中优化的序列化 AST 方法, 极大程
度地减少了代码的冗余特征, 并且缩短了模型的特征序列的长度, 进而减少了数据存储和传输中的能量消耗,
最终节省了计算资源.
图 4 模型在 AST 序列长度上的对比
3.4.5 参数分析
REcomp 作为预训练模型, 其性能受到参数的影响. 因
此, 本小节就实验中重要的几个参数之一的训练批量大小进
行讨论. 本文选择语义代码检索任务里的随机一种编程语
言, 本次实验的随机结果是 Ruby 语言, 以此进行实验, 其余
参数与微调时相同, 训练轮数设置为 2, 实验结果如图 5 所
示. 从图 5 中可以看出, batch size 越大, 检索任务的准确性越
高. 因此, batch size 对检索结果起正向作用. 但是 batch size
过大, 会导致训练时占用显卡资源过多; 而且, 当 batch size
达到某个阈值时, 模型在性能上的增长趋于平缓, 但资源上
的消耗却更大了. 因此, 考虑到这一点, 本文将 batch size 设
置为 64. 图 5 批量大小与准确性的相关性
3.4.6 案例分析
DeepCS [37] 提出 : 在 向量空 间中 , 两个 向量语 义越 接近 , 其距 离越小 . 基 于这个 前提 , 本文从
CodeSearchNet [33] 中随机选取 7 个功能不同的源代码, 作为 7 个类别. 如图 6 示: 用 7 种不同颜色表示 7 个类
别, 相同颜色的不同符号具有语义等价性, 圆形、菱形和三角形分别表示原始样本、PL 型正样本和 NL 型正