
Page 31 - 《软件学报》2021年第12期
P. 31
阳名钢 等:求解二维装箱问题的强化学习启发式算法 3695
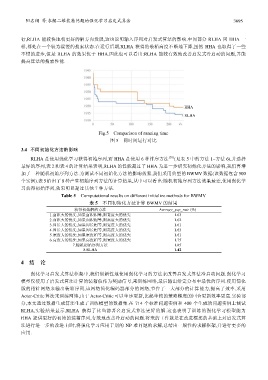
行,RLHA 能较快地朝更好的解方向发展,这也说明输入序列对启发式算法的影响.中间部分 RLHA 同 HHA 一
样,都处在一个较为缓慢的搜索状态.在运行后期,RLHA 获得的装箱高度不断地下降,虽然 HHA 也取得了一些
不错的进步,但是 RLHA 的效果优于 HHA.因此也可以看出:RLHA 能较有效地改善启发式冷启动的问题,并能
提高算法的搜索性能.
HHA
RLHA
Fig.5 Comparison of running time
图 5 同时间运行对比
3.4 不同初始化方法的影响
RLHA 是使用强化学习获得初始序列,而 HHA 是使用 6 种排序方法 [39] (见表 5 中的方法 1~方法 6),并选择
最好的序列,表 2 和表 4 的计算结果表明,RLHA 的性能超过了 HHA.为进一步研究初始化方法的影响,我们再增
加了一种随机初始序列方法.为测试不同初始化方法的影响效果,我们采用典型的 BWMV 数据(该数据包含 500
个实例).表 5 给出了 8 种产生初始序列方法的计算结果,从中可以看出:随机初始序列方法效果最差,使用强化学
习获得初始序列,效果明显超过其他 7 种方法.
Table 5 Computational results on different initialize methods for BWMV
表 5 不同初始化方法计算 BWMV 的结果
获得初始解的方法 Average_gap_rate (%)
1.63
1.面积大的优先,如果面积相等,则宽度大的优先
2.面积大的优先,如果面积相等,则高度大的优先 1.62
3.周长大的优先,如果周长相等,则宽度大的优先 1.61
4.周长大的优先,如果周长相等,则高度大的优先 1.63
5.宽度大的优先,如果宽度相等,则高度大的优先 1.61
6.高度大的优先,如果高度相等,则宽度大的优先 1.75
7.随机初始序列方法 1.85
8.RLHA 1.42
4 结 论
强化学习启发式算法框架中,我们创新性地使用强化学习的方法来改善启发式算法冷启动问题.强化学习
模型仅使用了启发式算法计算的装箱值作为奖励信号,来训练网络,最后输出给定分布中最优的序列.使用简化
版的指针网络来输出装箱序列,该网络简化编码器部分的网络,节省了一大部分的计算能力,提高了效率.采用
Actor-Critic 算法来训练网络,由于 Actor-Critic 可以单步更新,比起单纯的策略梯度的回合更新效率更高.实验部
分,本文通过数据生成算法生成了训练模型的数据集.在 714 个标准问题实例和 400 个生成的问题实例上测试
RLHA,实验结果显示,RLHA 获得了比当前著名启发式算法更好的解.这也表明了训练的强化学习模型能为
HHA 提供更好的初始的装箱序列,有效地改善冷启动的问题.将来的工作就是在改进框架的基础上对启发式算
法进行进一步的改进.同时,将强化学习应用于别的 NP 难问题的求解,总结出一般性的求解框架,并进行更多的
应用.